
The metaverse world has not yet arrived. As the first batch of people in the metaverse, virtual humans have already appeared on major screens. A-SOUL, Zhi Bing, Cui Xiaopan, Xi Jiajia... These virtual people have almost become familiar friends of the Generation Z.
The origin of virtual humans can be traced back to Lynn Minmay, the heroine of the classic Japanese cartoon "Macro Stronghold" in the 1980s. Lynn Minmay was the beginning of virtual idols. The animation company released records with her virtual image. Virtual humans entered the real world for the first time. From 2000 to 2016, virtual humans were still in the research stage. Since 2016, the emergence of deep learning and the metaverse has made virtual humans popular all over the world overnight.
According to the different driving methods, virtual digital human can be divided into AI intelligent driving type and real person driving type (motion capture technology). Human operation and motion capture equipment enable virtual digital humans to interact with audiences in real time. The AI intelligent-driven virtual digital human can automatically read, analyze and recognize the external input information through the intelligent system, decide the subsequent output text of the virtual digital human according to the analysis results, and then drive the character model to generate corresponding voices and actions to make the virtual digital human follow. User interaction. For the lip and micro-expressions of virtual humans, due to the large number of micro-motions and the huge cost of live-action shooting, AI voice lip-driving has become the mainstream.
AI Voice Drives Virtual Human Micro-Expressions
AI voice drive, also known as avatar voice animation synthesis technology (Voice-to-Animation), allows users to input text or voice, and generate corresponding 3D avatar facial expression coefficients through certain rules or deep learning algorithms to complete 3D Precise driving of the avatar's mouth and facial expressions. Allow developers to quickly build rich avatar intelligent-driven applications, such as virtual host news broadcasts, virtual customer service, virtual teachers, etc. According to the different input content (text/voice), it can be divided into three driving methods:
Voice Driven
Voice as the driving source. The speech is input into the deep model, which predicts mouth shape and facial micro-expression coefficients. The method is not limited to the voices of different people and countries. However, it has a strong correlation with speech and is greatly affected by speech characteristics (timbre, intensity, noise, etc.), so it is difficult to improve the generalization ability of the model.
Phoneme Drive
Text as a driving source. Convert text time series to phoneme time series and input into deep model to predict mouth shape and facial micro-expression coefficients. This method has nothing to do with speech, and is only related to text content, and is not affected by voice timbre transformation. However, the model is limited by the text languages of different countries (Chinese and English, etc.); the same text content, different types of synthesized voices, and the same lip-expression animations are synthesized, so the style does not have characteristics.
Speech and Phoneme Multimodal Fusion Driver
Use voice and phoneme as the driving source at the same time. The information of the two modalities of speech and text is fused by this method, and the driving coefficient is more accurate, but the model is more complicated.
AI-Driven Virtual Human Whole Body
In addition to the above-mentioned AI voice-driven facial expressions and lip movements of virtual humans, Baidu has recently launched an algorithm framework for voice-driven head, mouth, body and limbs and other whole-body movements, called Speech2Vedio, which is a synthesis of human body motion from voice and audio input. (including head, mouth, arm, etc.) video tasks. The resulting video should be visually natural and consistent with the given speech. The authors of the paper embedded the 3D skeletal knowledge and the personalized speech gesture dictionary learned by the model into the learning and testing of the entire model. Through the knowledge of 3D human skeleton, the generated movement range is limited, so that it does not conform to the range of normal human limbs. The voice-driven algorithm can synthesize movements that match the voice scene to form a coherent virtual human image with a unified mouth and hands. The algorithm flow is as follows:
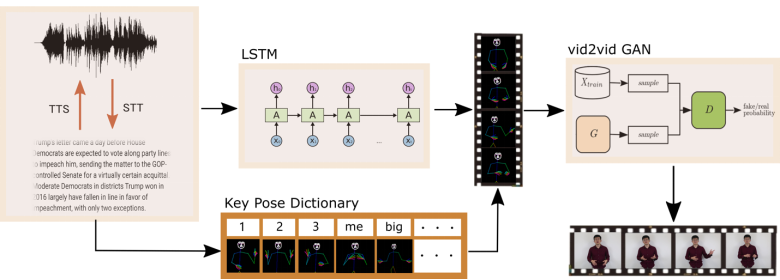
The input to the system is audio or text, which is used to train the LSTM deep model. Audio and text are interchangeable using text-to-speech (TTS) and speech-to-text (STT) technologies. The main purpose of the LSTM network is to map text and audio to body shapes. False STT outputs are usually words that sound similar to their true pronunciation, which means that their spelling is also likely to be similar. So the body shapes they will end up being mapped are more or less similar. The output of the LSTM is parameterized by a 3D joint model of the human body, face, and hands into a series of human poses, and then the final avatar image is synthesized through a GAN (generative adversarial neural network).
Voice AI-driven virtual human is the core technology of virtual human landing at present. This technology greatly saves the cost of virtual human production, and at the same time finely cultivates the coordination of virtual human hands.