
This dataset consists of 180 hours of transcribed Mandarin Chinese spontaneous conversational speech contributed by 663 speakers.
Sample:
Description
Open-Source MagicData-RAMC:
A Rich Annotated Mandarin Conversational (RAMC) Speech Dataset
180 hours of Mandarin Chinese dialogue, 150, 10 and 20 hours for the training set, development set and test set respectively.
Collection setup
The acoustic environments are small rooms under 20 m2 in area, and the reverberation time (RT60) is less than 0.4 seconds. The environments are relatively quiet during recording, with an ambient noise level lower than 40 dB(A).
The audios are recorded by Magic Data Technology Co., Ltd. over mainstream smartphones, with the ratio of Android and IOS systems around 1:1. All recording devices work at 16 kHz, 16-bit to guarantee high recording quality.
The datasets have been transcribed by Annotator, an AI-assisted Annotation Platform. The hesitations, repetitions, punctuations, non-speech and voice activity timestamps are annotated for high quality and informative labeling.
The gender and demographic distributions are balanced.
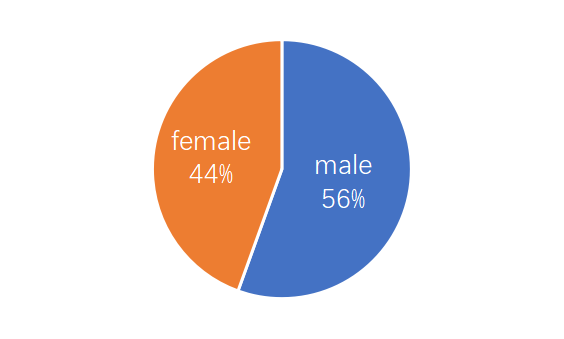
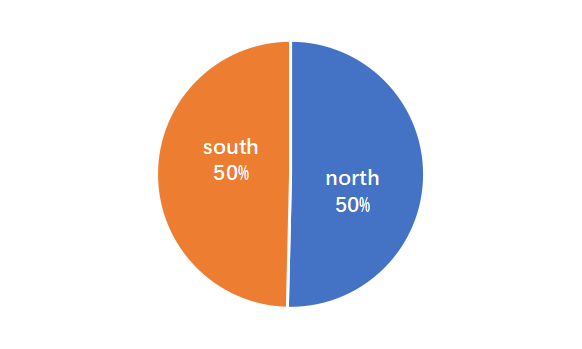
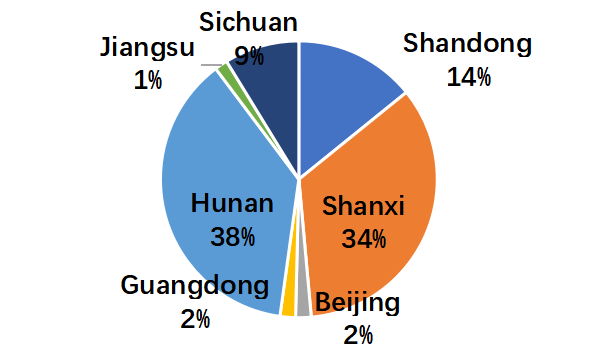
There is a wide variety of topics.
It contains 351 multi-turn dialogues, each of which is a coherent and compact conversation centered around one theme.
It covers 15 topics, including humanities, entertainment, sports, military, finance, religion, family life, politics, education, digital devices, environment, science, professional development, art and ordinary life.
It is suitable for exploring speech processing techniques in dialog scenarios.
Baseline
Automatic Speech Recognition
We used ESPnet2 toolkit to train a Conformer model. The training data includes 755h of MagicData-READ and 150h of MagicData-RAMC.
We achieved character error rates of 16.5% and 19.1% on the development set and test set, respectively.
Keyword Search Task
We retrieved 200 keywords, which is provided by MagicData-RAMC, based on the Conformer model and daynamic time alignment algorithm.
The precision and recall rates are 86.98% and 89.57% on the development set, and 85.87% and 88.79% on the test set.
Speaker Diarization Task
We used Kaldi toolkit to build a speaker diarization system which includes speaker activity detection, speaker embedding extractor and Bayesian HMM clustering. The timestamps are provided by MagicData-RAMC.
We achieved diarization error rates of 5.57% and 7.96% on the development set and test set, respectively.