

At the Tesla AI Day event, Tesla released the first version of the Optimus robot, and the technical details of the self-driving Full Self-Driving Computer (FSD). It included the perceptual neural network Occupancy Network (grid network) of pure electric vehicles (BEV), Interactive Planning (interactive planning), Lanes Network (lane grid), and Auto Labeling (automatic labeling). Visual automatic driving technology.
Occupancy Network
The Occupancy Network is a milestone in pure visual autonomous driving technology, which is a 3D reconstruction representation method based on learned function space.
Compared with the traditional multi-view stereo geometry algorithm, this method of learning the model can encode rich prior information in the 3D shape space, which helps to solve the ambiguity of the input. The comparison of different outputs of its 3D representation discretization is shown in the following figure. It can be seen that the raster network data is the clearest.
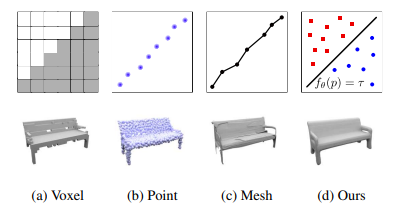
From the paper: Occupancy Networks: Learning 3D Reconstruction in Function Space
Approaches to generative models have achieved good results on high-resolution images, but have not yet replicated in the 3D domain. Compared to the 2D domain, there has been no agreement on a 3D output representation that is both memory efficient and can be effectively inferred from the data.
This technology is used by Tesla in the field of autonomous driving. Occupancy Network expands the 2D BEV space by adding the dimension of height on the basis of HydraNet. It first performs MLP learning on the feature map of the image to generate Value and Key, and passes the grid in the BEV space. The position encoding of grid coordinates is used to generate Query. The difference between the new grid is that the original 2D grid and height are used to form a 3D grid, and the corresponding generated features are also changed from BEV features to Occupancy features.
Interactive Planning
Interactive planning is very important in autonomous driving. This time Tesla mainly uses interactive search to solve the interactive modeling of complex intersections. Interactive search is divided into three steps: tree search, neural network trajectory planning and trajectory scoring. Planning is another important module of autonomous driving, and Tesla this time focused on modeling interactions at complex intersections.
Why is interaction modeling so important? Because the future behavior of other vehicles and pedestrians has certain uncertainties, an intelligent planning module needs to predict various interactions between the self-vehicle and other vehicles online, and evaluate the risks brought by each interaction, and Ultimately decide what strategy to take.
Its interaction planning is divided into three steps:
(1) Tree search is trajectory planning, which can effectively find various interactive situations and find optimal solutions, but the biggest difficulty in solving trajectory planning problems with search methods is that the search space is too large.
(2) After the target is determined, a trajectory to the target needs to be determined. Traditional planning methods often use optimization to solve this problem. It is not difficult to solve the optimization, and each optimization takes about 1 to 5 milliseconds. However, when there are many candidate targets given by the tree search in the previous steps, the time cost we cannot burden. Therefore, Tesla proposed to use another neural network for trajectory planning to achieve highly parallel planning for multiple candidate targets.
(3) After obtaining a series of feasible trajectories, select an optimal solution. The solution adopted here is to score the obtained trajectories. The scoring solution combines artificially formulated risk indicators and comfort indicators, and also includes a neural network scorer. Through the decoupling of the above three steps, Tesla implements an efficient trajectory planning module that considers interactions.
Lanes Network
Tesla's lane grid network borrows the Vector Lane module from the Shendu learning language model.
The idea of the whole module is to encode the lane line related information including the lane line node position, lane line node attributes (starting point, middle point, end point, etc.), bifurcation point, junction point, and the geometric parameters of the lane line spline curve. It is similar to the encoding of the word Token in the language model, and then processed by the time series processing method. In terms of model structure, Lanes Network is a Decoder based on the perceptual network architecture. Decoding a series of sparse, connected lane lines is more difficult than decoding the Occupancy and semantics of each pixel, because the number of outputs is not fixed, and there is a logical relationship between the outputs.
Auto Labeling
Data is the cornerstone of AI algorithm training and correct decision-making. The Auto Labeling introduced by Tesla at this event is the labeling on Vector Space, which needs to analyze and process the data and build a data labeling tool.
An offline large model is used to label the data, and the on-board model is equivalent to distilling the large model; and it has powerful data collection capabilities. Its core technology uses algorithms such as 3D reconstruction and visual SLAM.
Tesla's emphasis on driverless data shows that data is the cornerstone of all deep learning models. Only when models are trained with sufficient, large, and high-quality labeled data can the robustness and accuracy be improved, but the accuracy of automatic labeling still remains unstable. The accuracy and reliability of data annotation need proofreading by human. A human-in-the-loop annotation measure may be the best practice for current data annotation. In MagicHub, we open some datasets that are manually labeled using the AI-assisted platform built by Magic Data Technology. For audio datasets, besides speakers’ utterance, sound segments without semantic information during the conversations, such as laughter, music, and other noise events, are annotated with specific symbols. Some examples are as follows: