

With the rapid global deployment of intelligent voice technologies, multilingual, diverse, and natural speech data has become a core foundation for training high-performance speech interaction models.Large-scale training data is a prerequisite for ensuring the coverage and diversity of these models. By learning from various speakers' expressions, models can enhance their generalization capabilities and improve rapid adaptation in zero-shot and other scenarios.
Drawing on years of expertise in conversational data, Magic Data has launched a series of large-scale multilingual full-duplex conversational speech datasets. These resources support key AI tasks such as ASR, TTS, and SLU, further accelerating the globalization of Voice AI applications.These cover Mandarin Chinese, English, Japanese, Korean, and Spanish, providing strong support for AI tasks such as Automatic Speech Recognition (ASR), Text-to-Speech (TTS), and Spoken Language Understanding (SLU). This release will further accelerate the globalization of Voice AI products.
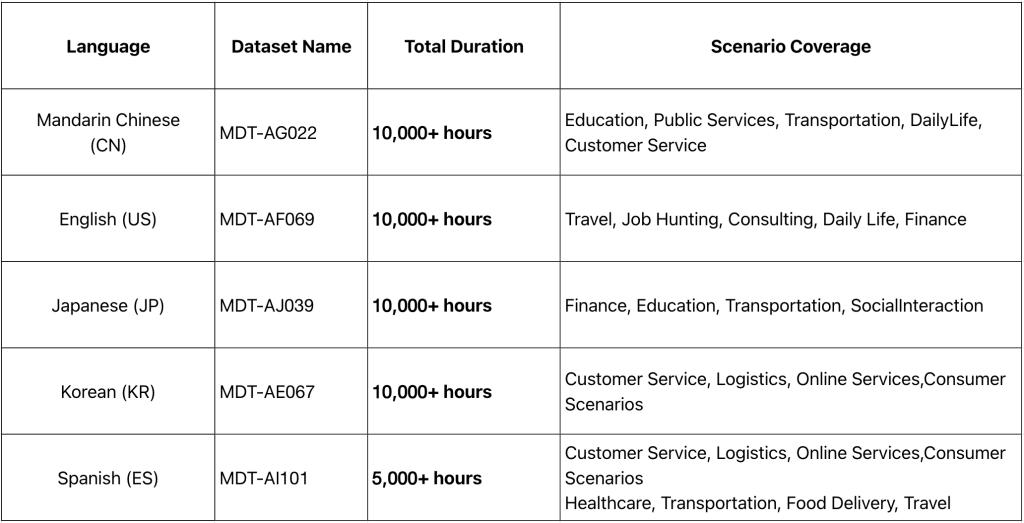
Overview of Released Datasets
For more info, please contact: business@magicdatatech.com
Dataset Highlights: Realistic, Comprehensive, and Practical
To better support the development and commercial deployment of multilingual Voice AI models, the Magic Data team focused on the following core advantages in the design of this multilingual dataset:
1、Large-Scale Full-Duplex Data Covering Real-World Scenarios
- Each dataset contains tens of thousands of hours of data, supporting large model training, fine-tuning, and testing.
- All recordings are dual-channel, full-duplex conversations, replicating real human-machine interaction processes.
- Diverse content covering high-frequency scenarios such as finance, education, healthcare, logistics, and more.
2、Localized Pronunciations with Broad Accent Coverage
- Japanese data includes major dialect regions such as Kanto and Kansai.
- Korean recordings feature native speakers, with a natural speech pace and standard accents.
- Spanish data incorporates both Latin American and European Spanish pronunciations to meet the needs of the broader Spanish-speaking market.
3、High-Quality Data Cleaning and Annotation
- All audio has been professionally cleaned and denoised to ensure usability.
- Rich metadata is provided, including highly accurate transcriptions, speaker information, semantic segmentation, and paralinguistic features.
- The dataset is clearly structured for seamless integration with speech training frameworks.
4、Commercial Licensing to Support Model Deployment
- All datasets are available for commercial licensing with clear copyright terms.
- Suitable for enterprise model deployment, academic research, and competition pre-research across various use cases.
Overview of Dataset Features by Language
🇯🇵 MDT-AJ039 Japanese Full-Duplex Conversational Dataset
👉🏻View Details:https://www.magicdatatech.cn/datasets/asr/mdt-aj039-japanese-duplex-conversation-training-dataset-1752133055
- High-Fidelity Independent Tracks: Clearly records dual-channel, full-duplex conversations, fully preserving natural interaction features such as overlapping speech, interruptions, and pauses.
- Multi-Speaker Annotation: Includes metadata such as gender, role, and paralinguistic features to support multi-dimensional semantic modeling.
- Rich Linguistic Features: Captures the Japanese honorific system, colloquial omissions, sentence-final expressions, and contextual logical connections.
🇰🇷 MDT-AE067 Korean Full-Duplex Conversational Dataset
👉🏻View Details:https://www.magicdatatech.cn/datasets/asr/mdt-ae067-korean-duplex-conversation-training-dataset-1752133360
- Independent Track Separation: Accurately separates overlapping speech and spontaneous interruptions, retaining authentic language behaviors.
- Emotional and Structural Features: Reflects Korean honorific structures, emotionally nuanced sentence endings, and rapid turn-taking in dialogue.
- Strong Cultural Adaptability: Helps AI better understand dialogue logic and emotional shifts in Korean cultural contexts.
🇪🇸 MDT-AI101 Spanish Full-Duplex Conversational Dataset
👉🏻View Details:https://www.magicdatatech.cn/datasets/asr/mdt-ai101-spanish-duplex-conversation-training-dataset-1752133891
- Complete Preservation of Dynamic Speech Behavior: Captures native speech characteristics such as intonation variation, collaborative speech, and natural interruptions.
- Fine-Grained Speech Separation and Annotation: Collected via independent channels, with multi-speaker annotation and scene classification.
- Adaptation to Speech Flow and Semantic Variations: Supports processing of rapid speech, colloquial expressions, and disfluencies, reflecting differences between Latin American and European Spanish.
For Mandarin Chinese and English large-scale full-duplex conversational datasets, please visit our website for details:
https://www.magicdatatech.cn/datasets
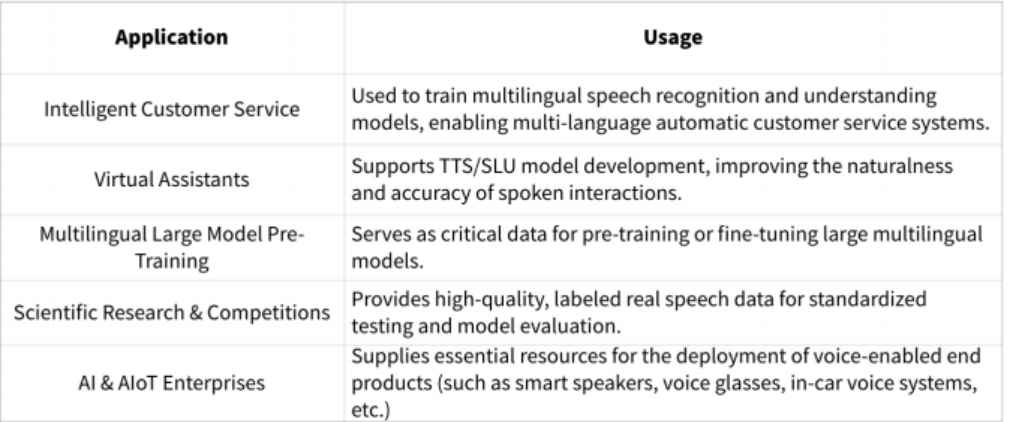
Who Can Benefit from This Dataset?
Magic Data's multilingual full-duplex conversational dataset can be widely applied in the following fields:
Why Choose Magic Data's Multilingual Speech Dataset?
Magic Data is committed to providing professional, secure, and high-quality data resources for Voice AI development, with the following core advantages:
Trusted and Compliant, Globally Recognized
- International Standard Certifications: Strictly follows ISO/IEC 27001 (Information Security Management) and ISO/IEC 27701:2019 (Privacy Information Management) standards.
- Clear Commercial Licensing: All datasets are collected and authorized through compliant processes, supporting commercial model deployment.
Wide Coverage and High Adaptability
- Multilingual Support: Covers major global languages including Chinese, English, Japanese, Korean, Spanish, French, and more.
- Multimodal Data Support: Provides audio, text, image, and audio-visual multimodal datasets.
- Multiple Data Types: Includes conversational, read, and spontaneous speech data, closely aligned with real-world application scenarios.
High-Quality Annotation, Training Ready
- Human-Machine Collaborative Annotation: Combines automated tools with human validation to ensure accuracy and consistency.
- High-Precision Text Alignment: Includes speech time stamps, speaker turns, paralinguistic information, and more.
- Standardized Data Structure: Compatible with mainstream Voice AI training frameworks for out-of-the-box use.
How to Get the Data?
For more details, please visit Magic Data's official website:
https://www.magicdatatech.cn/datasets
To apply for a trial, request other languages, or explore cooperation, please contact: