
作者:付强
编辑:麦吉哈
在Data & AI Con Shanghai 2023的“数据工程与大模型落地实践”分会场中,之江实验室高级研究专家付强老师为我们分享了「自适应深度学习语音前端处理」,让我们对语音处理这一领域有了更深入的了解。
多声源场景中目标语音的分离或提取,或称“鸡尾酒会”问题,建立了从基于统计信号处理的盲源分离统一框架到与深度神经网络相结合的神经波束形成器等深度信号处理的技术迭代路线,声学先进算法的多声源分离性能和收敛性不断提升,提升了环境噪声和大回声下的唤醒和识别能力。
自适应深度学习
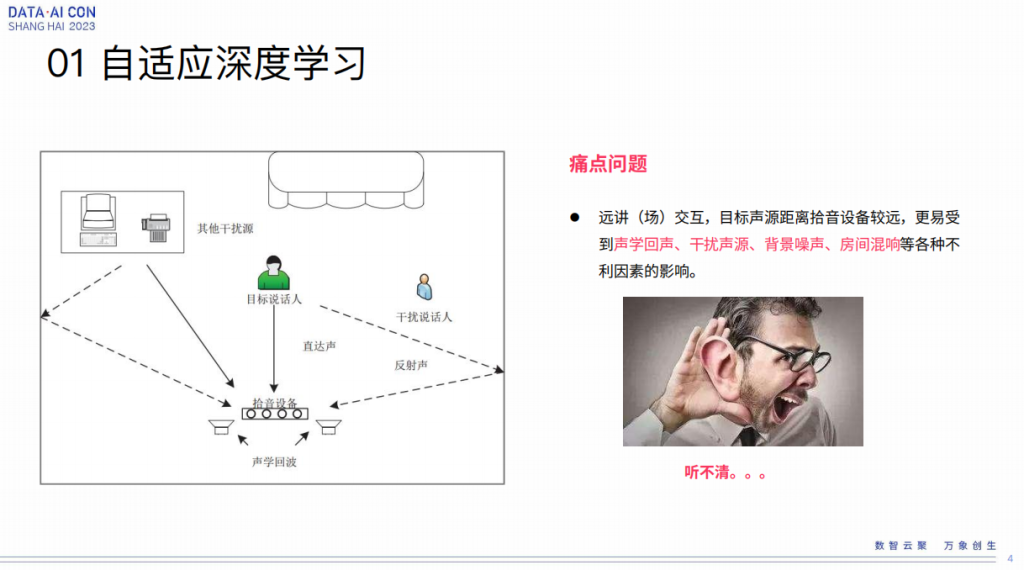
自适应深度学习这个词是我编的,网上查不到,因为我也在探索这个话题,过去前端要解决几个问题,包括回声干扰、背景噪声、房间混响等等,从声学上来讲不同的不利因素对声音的影响也不同。

经过了这么多年的发展,大家还是解决了很多问题。但到现在来讲,在这个地方还有几个问题并没有彻底解决。第一个是全双工,但这个问题已经逐渐有一些很好的方案出现了,比如人机对话的时候,我说话和对方讲话有些强化,怎么做更好的双讲,做得透明。第二比较重要,就是所谓的鸡尾酒会,是说在一个场合里面有很多人在讲话,怎么能有一个很好的机制能够选择性的注意到某一个人的声音,能够屏蔽掉别人的声音或者背景的干扰,对于机器来讲,这个问题依然是一个很难的事情,没有被彻底解决。第三是极低信噪比,比如扫地机这种极低信噪比,虽然它对一个信源特性区分性很强,但是它信噪比毕竟很低,这也是一个比较头疼的事情。
在这样的情况之下,这些技术可能在使用过程中还不能够发挥的淋漓尽致,这就是我们希望能更好的解决这个事情的动机。
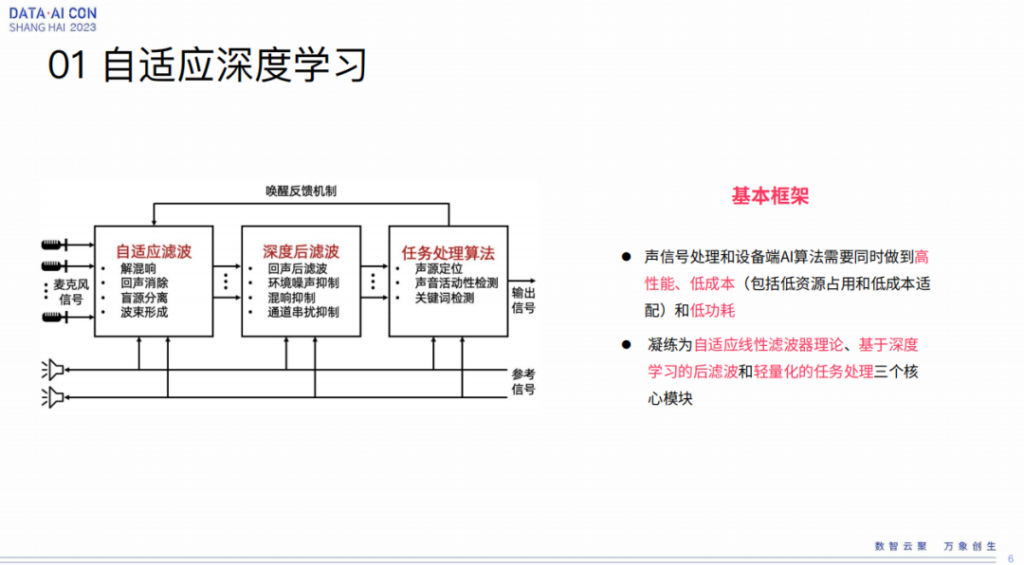
所谓自适应学习这个理念,简单来讲,目前就是这样一个框图,这并不够从方法论角度去想问题,只能代表我们过去多年的一个探索。
那这个是什么意思呢?无论是什么样的语音交互任务,无非就这几个环节,对声音的处理,包括混响的处理,回声处理,统称为自适应滤波。如果在物理条件下能够把自适应线性滤波器理论用得淋漓尽致,那还是尽量用,这是我们各种实践和测试得出的一个心得。因为纯的端到端的神经网络,在数据不足够充分的情况下,其实还不能够达到传统信号处理所能做到的效果,这是我们自己的一些经验。当然,在nn这样数据驱动的条件下,我们无论是对于回声、环境噪声、混响以及所谓的通道串扰都有非常好的效果,我们称之为深度后滤波,这个是比较合理的。我们希望在一个经典的线性理论框架之下能够交叉融合,使得这两种方法论无论是在更广泛的条件下还是更极端情况下,都能有更好的联合效果,这是我们所期待达到的目标,所以我们称之为深度后滤波模块。
其后才是我们的任务处理,端侧来讲可能做的比较多,类似于camera sporting这种,后边还有一个识别,所以基本上来讲是包含了自适应线性滤波器理论以及基于深度学习的后滤波和轻量化的任务处理三个核心模块。因为过去我们更多的是做端侧,所以才这么说。我们抛开端侧不管,其实对语音识别的任务都是一样的。特别要说的是在这个机制里,有一个所谓的唤醒反馈机制,其实它不一定是唤醒反馈。总而言之,从任务到前端的反馈是我们认为在这个过程中比较重要的一点,这也是跟人的听觉机制感知非常像,所以一定程度上来讲,这个是从类人的仿生角度出发来考虑问题。

在这框架之下,我们有几个具体的工作点。在自适应滤波这块有一个统一框架,因为过去我们这个团队做盲源分离的算法会比较多一点,特别是在实践过程中,对它复杂度的理解在国内来讲做的比较早,实践的也比较早,所以对它的理解比较深刻,拿它出来解剖,基于盲源分离、解混响和回声消除一体化,这个是我们在理论层面做的一个贡献。
过去盲源分离和解混响、回音消除怎么统一框架,没有人很深入探讨过,这是我们做的一个理论贡献,所以我们认为目标声源、干扰声源、回声声源建模是各自独立的信号过程,也符合盲源分离对于独立信号的分离,所以通过最大化信号源之间独立性对各声源进行分离完成统一的解。从理论上来讲,模块之间的级联进一步提高,过去这个过程是通过不同的算法模块去做的,在我们的理论框架里是一个算法。以上就是我们在线性滤波这块做的一些差异化工作。
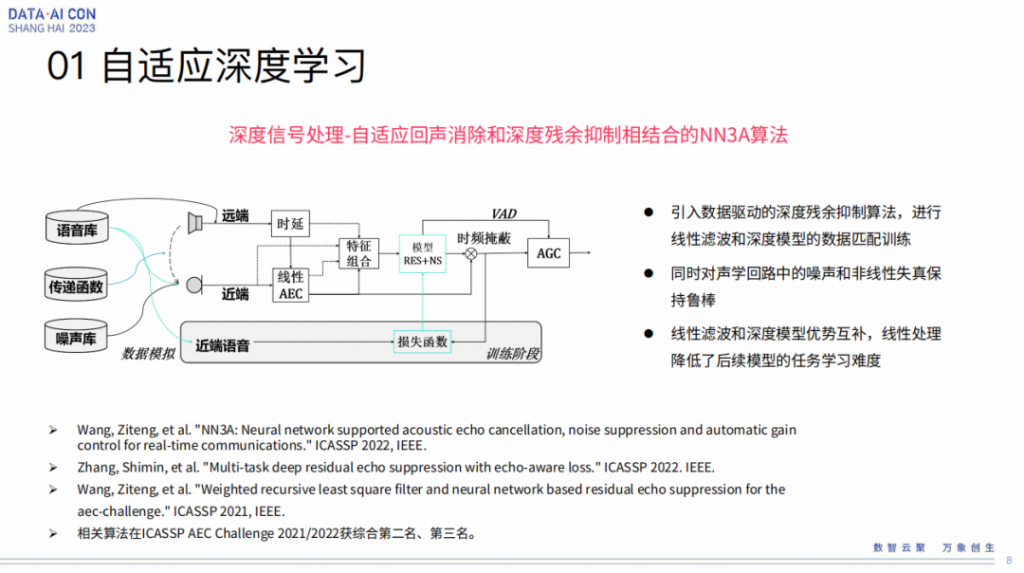
接着说所谓的深度信号处理这个概念,这是我们刚才讲的深度学习后滤波说法的一个延展。特别是在这个工作里,我们在AEC场景之下把自适应回声消除和深度残余抑制相结合的NN3A算法,也是我们率先提出来的。
从理论上来讲,在传统的AEC框架上引入了数据驱动的参与阈值,这个效果相对比较鲁棒,它也是更有经验的。所谓的数据驱动,因为它本身是一个DFA,解决非线性问题的,如果是线性问题,线性滤波肯定是最好框架,那非线性问题,最好用非线性模型去解,所以这也是非常straightforward的一个想法,在这里面NN的理论也很自然,这个效果确实也是不错的。当然一定要有一个匹配训练的过程,这样效果才能发挥到最佳。这就是我们在深度后滤波这边比较早期的工作。
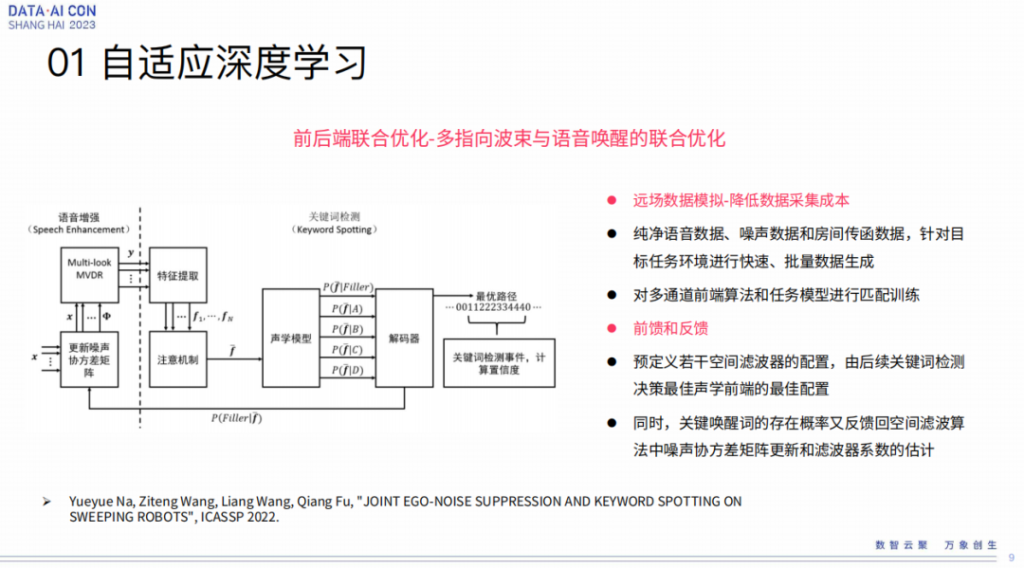
接下来我们讲的是前后端联合优化,主要体现在声学前端和唤醒之间的联合优化。假设唤醒是个任务模块,这个任务模块和前端处理怎么做联合优化,这也是我们做的比较有特色的一个工作。上面这张图你可以看到在speech enhancement这块,我们有类似MDR这样经典的自适应波速形成,但是它有一个噪声协方差矩阵的模块被独立拿出来讲,这个东西跟后边Keyword Spotting是有联系的,也就是说我们可以根据后边解码出来的唤醒的进度,在线去调整跟前端相关的噪声协方差矩阵。
这也是这篇paper能够被录用的一个点,是我们最早把这个引进来去做这个事情,当然这跟我们这边一个注意机制有关,我们也是从人耳的听觉系统中借鉴的这个东西,在实践中我们也这么做了,的确也是有效。为什么这个效果拿出来讲,因为利用这个我们做了国内第一台在扫地机上能够做语音唤醒的一个语音算法,两年前跟科沃斯合作,第一次商业化的落地也是由我们来做的。所以在那样极低性噪比的情况下,把这个方法实践也是我们成功的地方,不只是简单写一个paper而已。
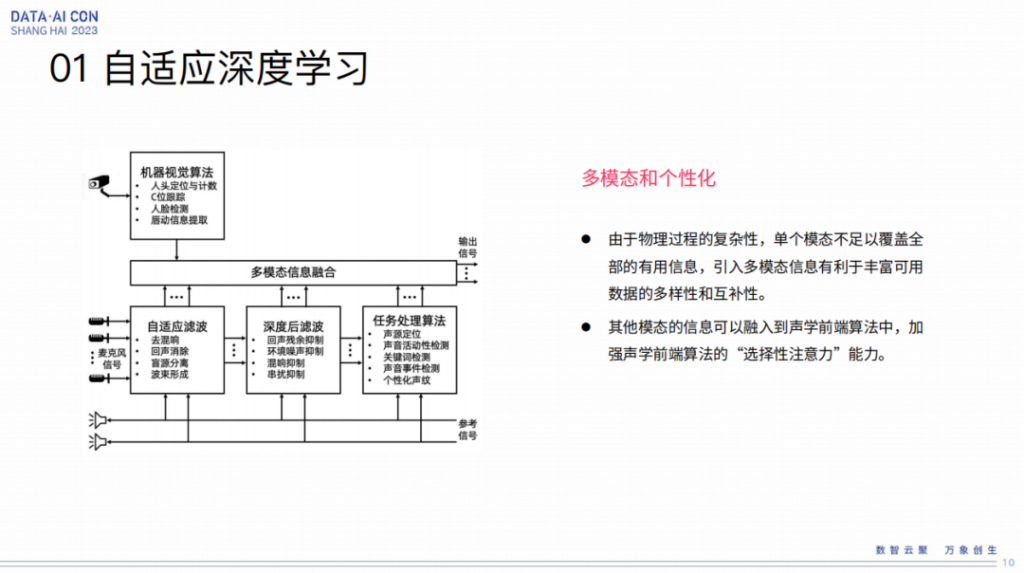
刚才讲的这几点都是纯声学链路上的几个模块以及相对的联合优化。其实对于前端来讲,即多模、个性化,也是大家正在做,或者未来的一个趋势,因为很多东西只是通过声学这样一个维度,或者特征层,它区分性毕竟也是有限的,因为人交流也不光只是声音本身,也可以通过表情、动作等等来理解,大家也都知道,所以大家会把这样一个信息量用计算的方式体现在前端里边。现在大家也各有各的做法,我们在这方面也有自己的一些心得,所以我把多模态和个性化都放在这里。总而言之,单模态不足以覆盖全部有用的信息,引入多模态有利于丰富可用的数据多样性、互补性。
为什么一定要这么做,还是从仿生机理来讲,我刚刚讲人的交流本身也不光是声学这一块,那么能不能用计算的方式实现前端的选择注意力,形成这样的能力也更鲁棒和好用,这是我们后边要发展的一个重点。
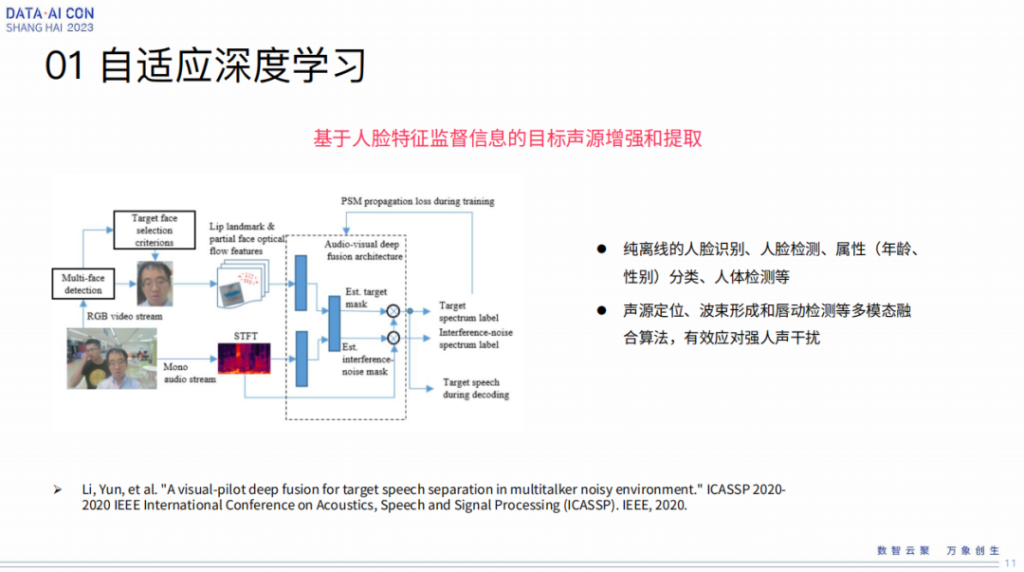
在这个逻辑下来讲,我们具体的工作点是基于,比如举个例子是基于人脸特征监督信息的目标声源的增强和提取,这个是2020年的工作了,这个工作看这个框图来讲也是比较straightforward,人脸更多还是唇动,但是抓人脸,不是只抓唇,通过人脸mask信息去抓到唇的动作信息给到mask,影响mask的构成,然后才会作用到声学提取的过程里,简单的思想就是这么个东西。
当然我们每一个工作背后不光是一个paper,都是对应一些实际落地的。举个例子,我们在2018年跟上海地铁有合作做语音售票机,就是用这样一个基本方法去做的,因为在那个场合里是免唤醒,不需要唤醒词,只要人过去它就可以张口说话。因为公共空间环境非常嘈杂,这里边语音抽取工作跟很多模型有关。
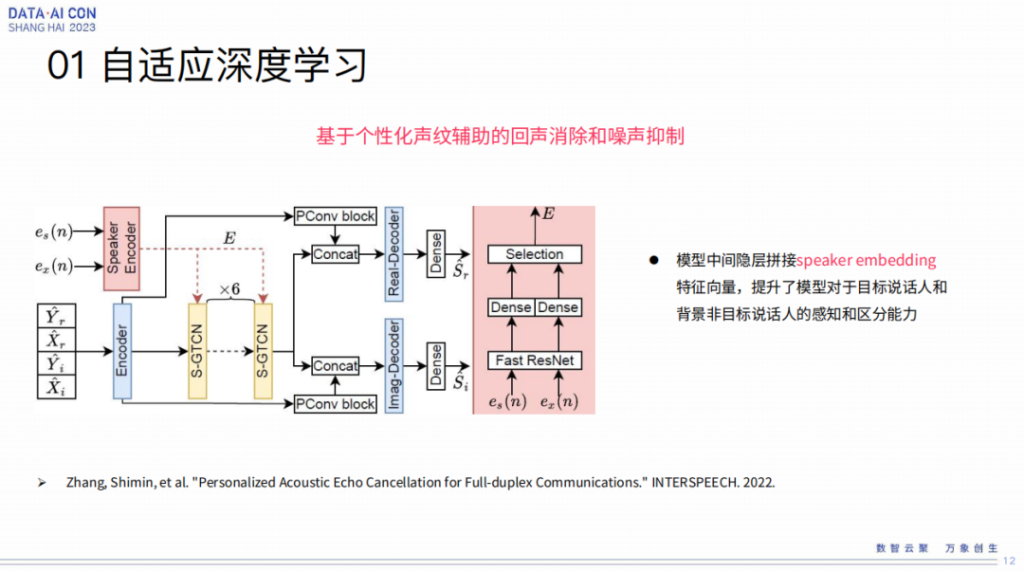
个性化声纹是跟谢磊老师团队一起合作的一个工作,体现在personalize的AEC里面。对于人的个性化信息,有更好的手段处理。所以类似于这样的工作,在AEC后滤玻端有没有更好的作用,也就是我们尝试的点。所以在后滤波的模型中间隐层拼接speaker embedding特征向量,提升了模型对于目标说话人和背景非目标说话人的更强感知和区分能力,这也是我们这个工作里体现出来的一个点。
模组方案与应用
刚才那几点是过去我们的研究和工作实践,我这边的特点,是每一个研究都跟一个实际应用挂钩,更多的是在落地应用中总结一些算法上的心得理念,所以每个工作都跟一些应用有关系,后边谈一些跟应用相关的事情,大家对对应的算法会有更多的理解。
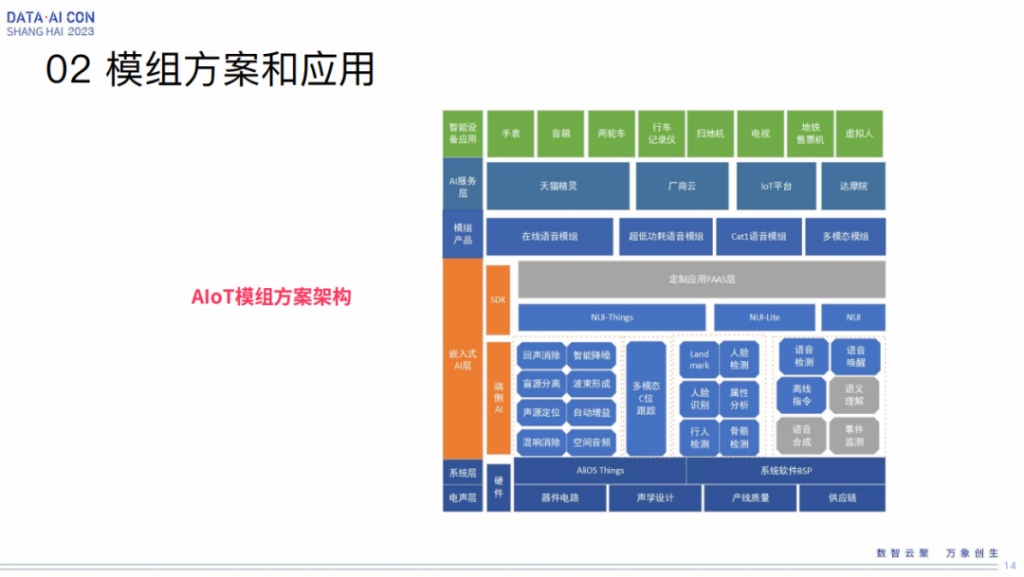
我在来之江实验室之前是在阿里达摩院,更多是面向LT、AIoT这个场景。这个图是一个非常宽泛的概念图,算法是在类似于端侧AI这一层,包括云的、视觉方面,通过我们自己团队和别的团队的合作,陆陆续续做了很多。但是我们也做过硬件模组的构建,以及跟不同的业务团队做不同的业务输出。

这是一个典型的模组,跟语音相关,一个是所谓的高性价比模组,我们面向更广阔的业务,比如面向音箱、家电等等,也是用基于国产的RISC-V的CPU跟拼多多合作做了两款语音芯片。
第二个是高性能语音模组,刚才讲到了类似移动机器人、扫地机这样比较高制造的设备,芯片的能力会更强。
第三个是多模态模组,面向地铁、商场这种高噪声的场所。

刚才讲的是几种比较典型的模组方案,但稍微特别讲一下,我们刚才讲到了语音芯片,这就是当时我们设计的低功耗高性价比的芯片,因为语音这个东西市场成本如果没有低到大家预期,实际上也很难推,所以我们强调高性能、低成本这个难度还是很高的。
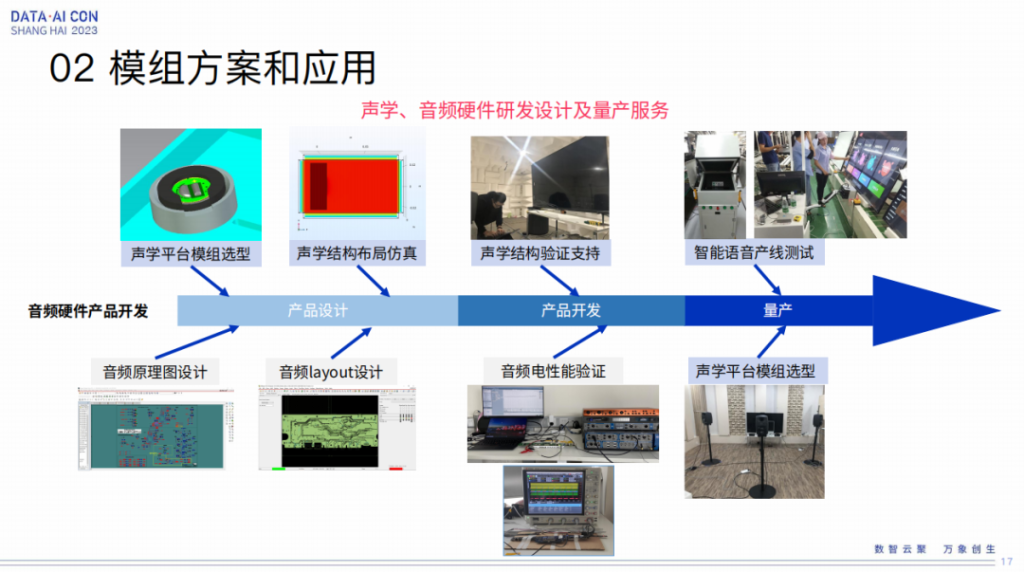
我们作为产品级的推广,除了算法硬件之外,也为一些声学的音频硬件的研发设计和量产服务,也是配套的能力。所以在这里面从产品的设计阶段到开发阶段到量产阶段,都是基于全程的配套服务,才能使这个东西真正的贴合产品落地。

上面是一些我们过去具体的样例,包括电视机领域、海尔、康佳全量等等这些东西。

高性能模组的落地刚才也讲了,一个是科沃斯业界首款的语音交互扫地机,这是我们第一个上线的东西,然后包括同样的模组,快速用在机器狗的里面。

多模态刚刚讲从2018年开始我们就在上海地铁开始落地,直到21年,大型地铁站还在上线。
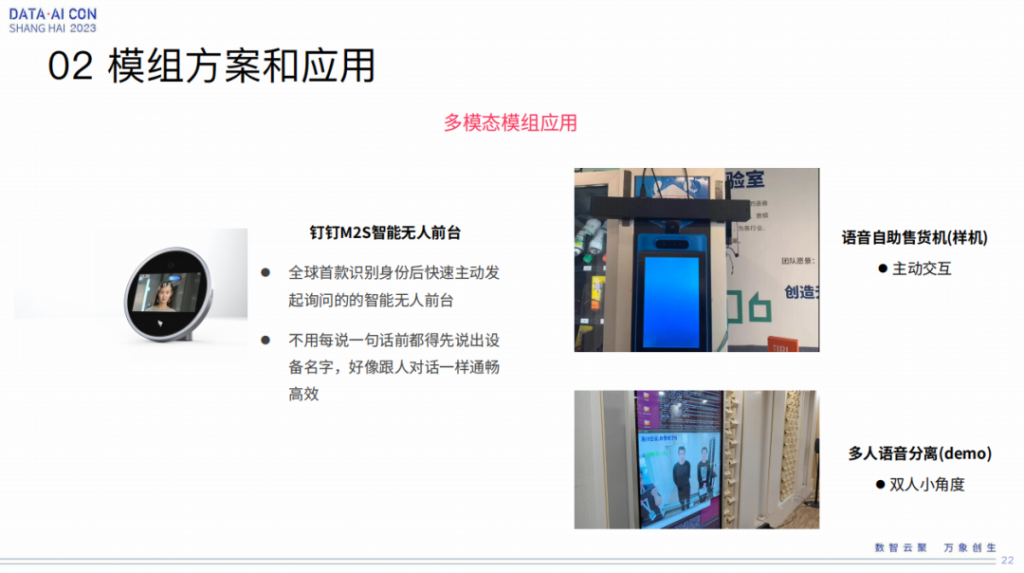
多模态后面陆陆续续的进展,包括跟钉钉合作的无人前台、自动收货机,以及去年我们还做了一些工作,包括多人的分离等等,这些还是样机还没有销售机,更多来讲是跟一些demo有关。
面向机器人的语音交互系统
第三个部分是面向机器人的语音交互系统,这个也是过去这些工作的延续。
我认为机器其实是基于音箱,你可以认为是一个面向家庭端的空间,它的声学场景相对来讲是比较好处理的,因为虽然距离远,但是距离远这个事情已经被克服掉了,环境干扰可能就是家里的电视机了,这个声音比较大,单一噪声来源还是有很多措施可以做的,所以音箱这个环节我相信大家也可以认为是逐渐已经被攻克了,这个问题已经被解决了。
现在大家可能做语音更多是在新能源车领域中做现实的工作,我过去很多同事都在车厂,他们要解决的类似于多音区这样的跟声音相关的工作。多音区的工作在车里面有好处,因为毕竟就那几个车位,相当于位置是比较固定的,人在这个交互过程中不会窜来窜去,就固定在那个区域里面,所以这种信息都可以被拿来利用,去做一些先验的东西,相对来讲也是没有那么难。
那么机器人难在哪里?主要是场景不固定,机器人可以在室内,可以在室外,也可以在公众场合,对于声音场景没有绝对先验的假定,那么周围的声学场景你也很难做一些很简单的假定,因为这个有可能比较安静,也有可能非常复杂,尤其一群人围观起来七嘴八舌,这个就是很大的一个挑战。如果是户外,可能有别的背景噪声。所以从技术角度来讲,机器人可能是所有的里面,最复杂也是最有挑战性的一个情况。如果在机器人领域中把前端问题彻底解决好,意味着交互前端可能基本上也没有什么太多的难点。
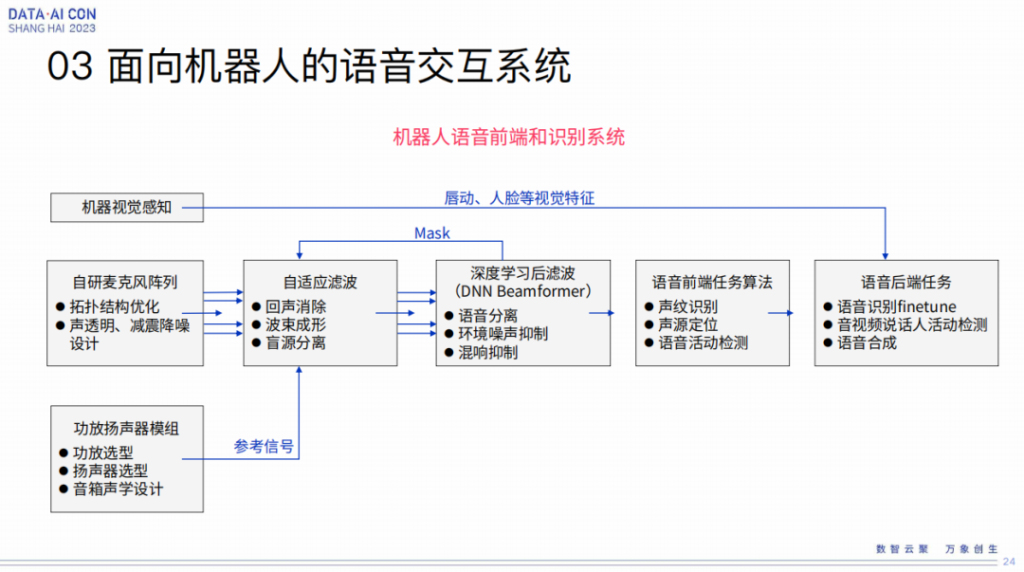
这张图基本上是目前在我们的集群里面所用的基本框架,基本的算法。大家可以看到,和我刚才讲的逻辑上是没有区别的,机器人确实是里边利用东西最多的,也是最复杂的,产生的问题也是比较challenge的。
浙江相对语音团队的资源没有那么丰富,但是我们在短短几个月时间做到了什么,我不能说做到全自研,但是最起码从他们过去强烈依赖于讯飞或者思必驰这样的外部供应商条件,变成了基本上可控,另外前端基本上是我们过去的积累加上之前的一些算法。在语音识别中,我们虽然现在用的是Paraformer,也就是阿里的开源框架,但是它提供了模型finetune的能力,这样就是能够在我不用从0到1写开源代码的情况下,能基于我们的数据做finetune。尤其是未来也留下的空间,既然它能够finetune,也就是能够跟我们的前端做联合优化,这就是我选择这个框架的一个点。对话基本也是我们自己做的,所以链路可控,各种性能模式可以控制的了,至少达到这么一个目标。
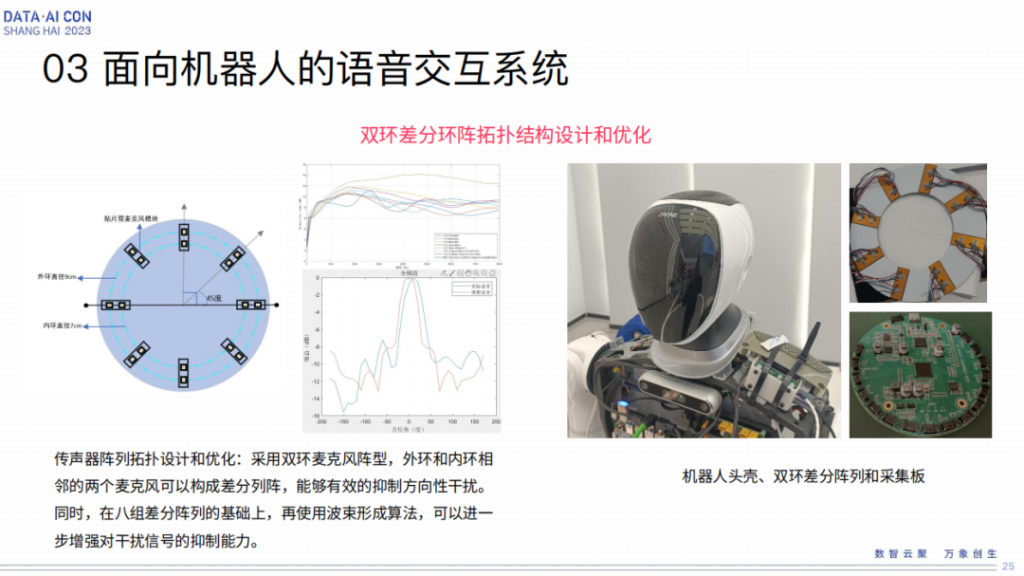
当然有些特殊的点,类似这个人形机器,也算是我们第三代的一个机器人产品了,其实做人形机器的本来就不多,浙江这个地方做人形机器人力量还是比较雄厚的,所以配合着这样一个东西,我们去做一个比较独特的工作,就是怎么样为机器人从传声器这一端做一些结构优化和设计优化。
最后,经过不断的仿真和持续测试,我们选定了双环麦克风阵型,总共有16个麦克风,内外两个环状的阵列排布,期待内外环首先构成一个差分阵,在声学理论中,差分阵是比较独特的一个,你可以想象成它组合起来是一个比较好的定焦麦克风,在这个基础之上再去做一般意义上的环形麦克风阵列,这样就是在八组差分阵列基础上再做波束形成,可以进一步形成对干扰信号的抑制能力,这是我们经过不断的各种仿真和实测得到的一个心得。
机器听觉展望
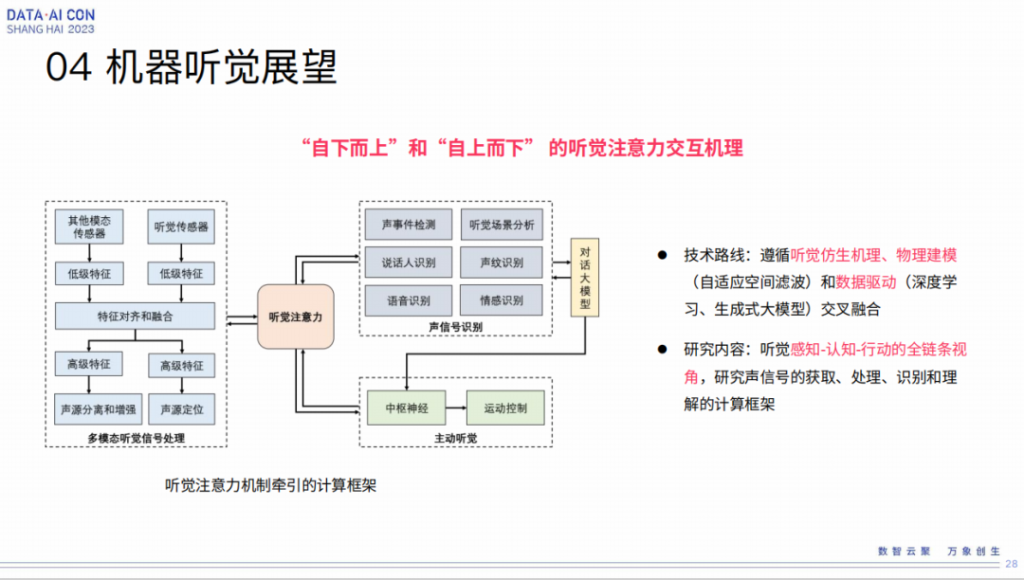
刚才讲的是我们的实践过程,大家可以发现其实是一步一步的这么走过来的。从存在信号处理这样的路线,到深度学习的引进,以及深度学习的融合和任务处理跟任务模块的联合优化,我们都是一步步的通过业务落地的检验取得的心得,这是我们这个团队工作的一个特色,都是跟实践高度结合起来。
但是从这里我们自己深刻感到的一个趋势,我们统称为机器听觉这个问题的解决。单从哪一个模块来讲,其实研究的空间可能都是有限的,还是要从全链路的视角,因为人的听觉的信息不是一个单向的信息蒸馏的过程,不单是一个从底层的事件驱动。更多来讲也会发现人在处理一个复杂产品的时候,它会自上而下、自下而上的双向交互,这个交点不是哪一个单纯的事件就能够左右的,人的大脑还是非常的复杂,结合了不同的情况,无论声学的某些事件信息,还是过去的历史经验的积累等等这方面综合信息的一个表达。
所以所谓的听觉注意力,就是一个自下而上和自上而下相互交叉的概念,这是我们的一个体会。所以我觉得这个问题包括大家所说的难点,比如我想听声音就产生什么声音,对于一个机器能非常灵活地选择,多人里面谁说了什么,或者下一段可能自己要做一个切换等等这些东西最终来讲还是有双向交叉的机理的结合。
所以遵循听觉仿生机理、物理建模、数据驱动,从我的角度来讲,可能是后面要遵循的一个大的技术路线,所以内容来讲,这是全链条的视角,甚至包括了行动。为什么说这一点,这张图其实有个主动听觉,这个概念在里面什么意思呢,是指人在听的时候,不光是被动的听觉,比如动下耳朵,头转一转都是实践你听觉注意的一种方式。
我们还是拿机器人举例,机器本身是可以运动的一个装置,不像智能音箱,只能被动的放在那里,机器人就可以动,这样对于听觉来讲就是添加了一个所谓的主动听觉的能力空间,那么从感知、认知到行动的全链条视角去研究声音的获取、处理、识别和理解,这是我们要做的一个新的计算框架。