
作者:谭钧心
编辑:麦吉哈
在Data & AI Con Shanghai 2023的“数据工程与大模型落地实践”分会场中,网易云音乐资深改造平台开发工程师谭钧心老师分享了「大模型在网易云音乐的落地实践」,从多场景、多任务等实际落地来介绍大模型的应用。
ChatGPT的出现,是人工智能技术发展的一次飞跃。无论是大模型本身还是大模型应用到业务,业界对于大模型的关注度越来越高。云音乐将大模型引入业务的工程化实践中,在仓储流程、资源管理、使用效率等方面遇到了一些现推广搜业务的问题。为了解决这些问题,云音乐制定了一套基础大模型训练、评估、部署的标准规范,并应用于现有的机器学习平台中,帮助算法人员迭代大模型到线上业务。
总述

接下来,我会讲一下我们的算法,包括现在很火的大模型,在网易云音乐的一些落地实践。我会分为三块来讲,第一块会介绍下云音乐机器平台建设的背景,以及相应的演进过程;第二块讲下云音乐在面向我们特定的一些场景时,怎么将大模型应用到具体的业务场景里;第三块讲下后续的一些规划。
背景概览
云音乐算法应用场景
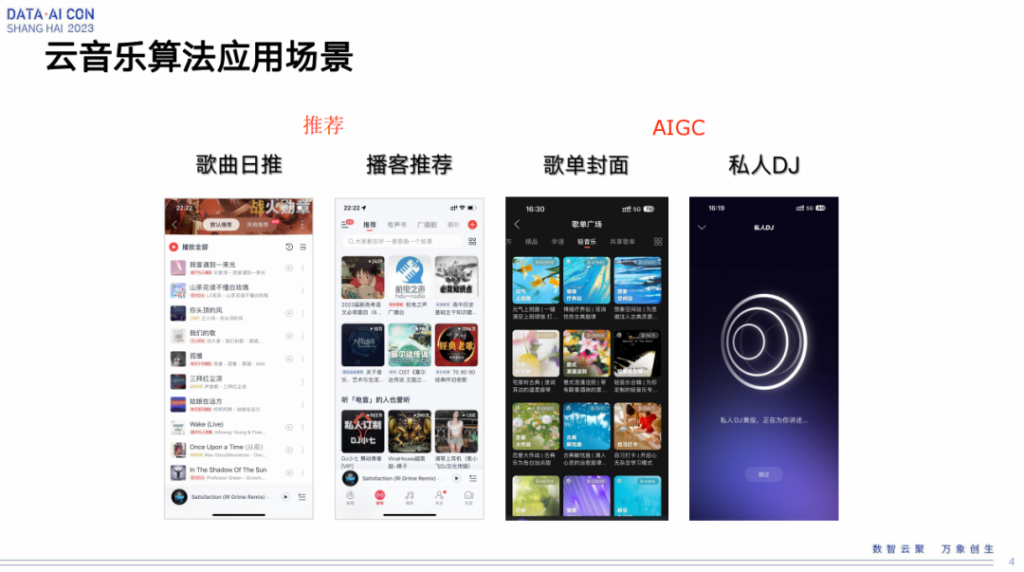
云音乐有很多算法场景,像我们以前很火的歌曲日推、播客推荐,当然还有其他的比如歌单推荐、歌单封面制作、私人DJ、对话聊天等等场景,主要就是分为推荐这一大类,再就是AIGC这一大类。
机器学习平台演进历程
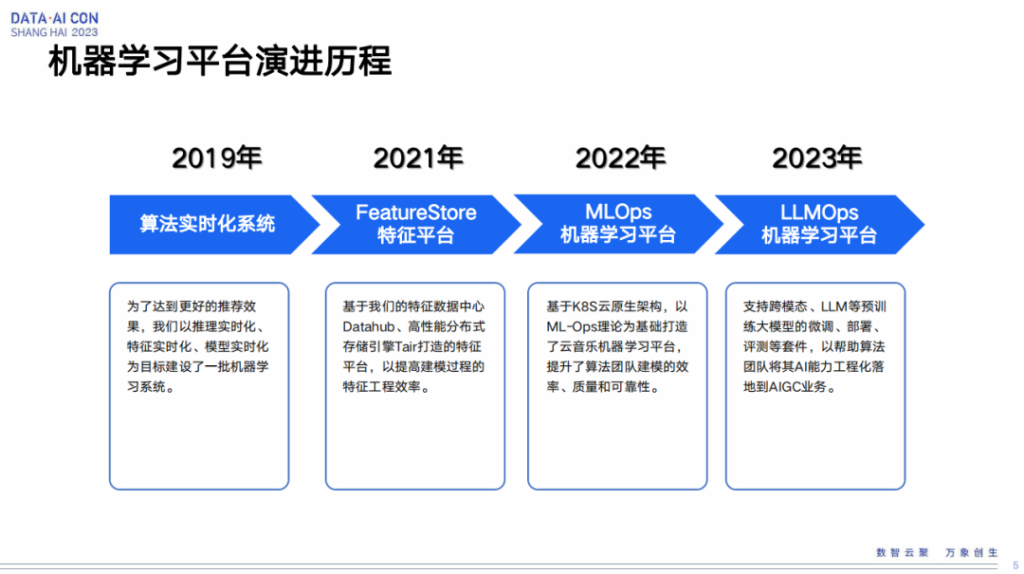
我们语音音乐的机器平台是从2019年开始的, 19年我们做了第一个事情,将我们的模型从离线搬到了线上,然后通过线上的实时预测来降低成本,也可以快速地应对我们线上业务的反馈。
2021年有一个很大的瓶颈在于模型的前期数据,其实就是特征的一个准备过程,当时特征碰到了很多的问题,第一个问题是特征存储的问题,第二个是特征的存取问题。我们基于遇到的问题以及线上业务场景的需要,打造了Tair引擎,然后基于Tair引擎做了一个叫做Datahub的数据统一存取的中心化工具。
2022年我们把特征做完之后,就会涉及到一个线上的模型,包括模型的开发测试,训练测试,然后到线上的部署,包括后期的运营等等一套完整的模型链路,那将我们的模型和我们的特征整合到一起,就形成了MLOps平台。
今年我们开始着手将大模型应用到我们的一些场景里面。云音乐应用大模型可以说从去年就开始了,但如果通过这种工程化或者标准化的手段去落地,其实应该是在今年的年中开始的。我后面会讲一下我们怎么通过工程化的手段将大模型应用到我们的场景里面去。
机器学习平台架构
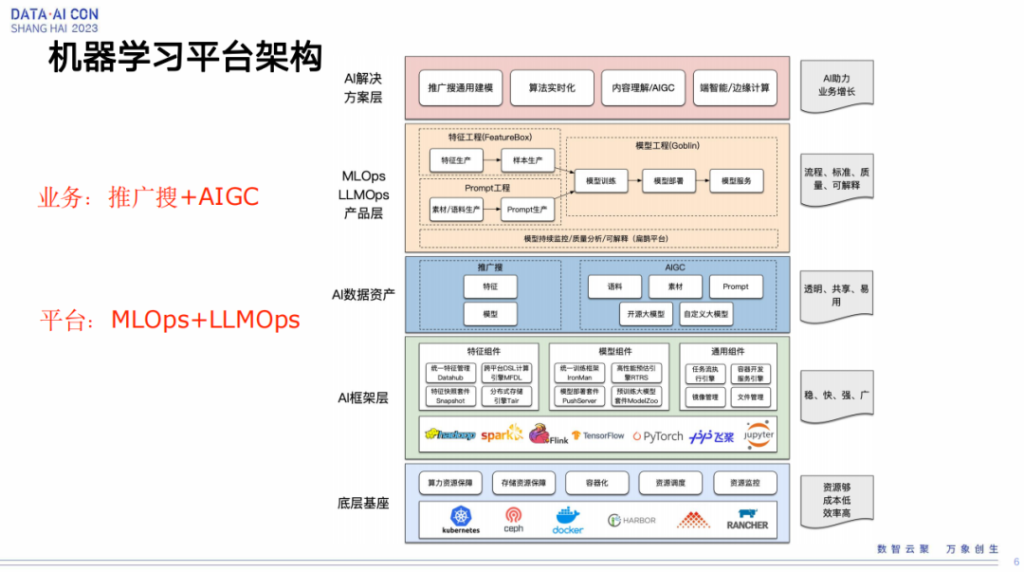
这是一个整体的平台的架构图,最上层是我们的AI解决方案层,就像刚才说的不仅仅是我们推广搜的一个业务场景,还包括项目端、NRP的场景、CV的场景,包括我们现在的一些大模型的场景,当然还包括边缘计算的场景。
再下面就是刚才提到的平台层,其实就是MLOps以及基于MLOps将我们的大模型的一些特殊问题解决完之后形成一些解决方案,然后赋予之上形成了LLMOps。从这边可以看到LLMOps相对于传统MLOps是有不一样的地方,最大不一样的地方就在于前期的prompt工程这块。
除了平台之外,我们还会基于我们的平台沉淀数据资产和模型资产。然后再下面就是各种框架,包括我们的特征处理框架、模型训练框架、模型部署框架。最下面是我们的资源管理,我们是通过kubernetes管理的。
大模型实践案例
LLMOps概览
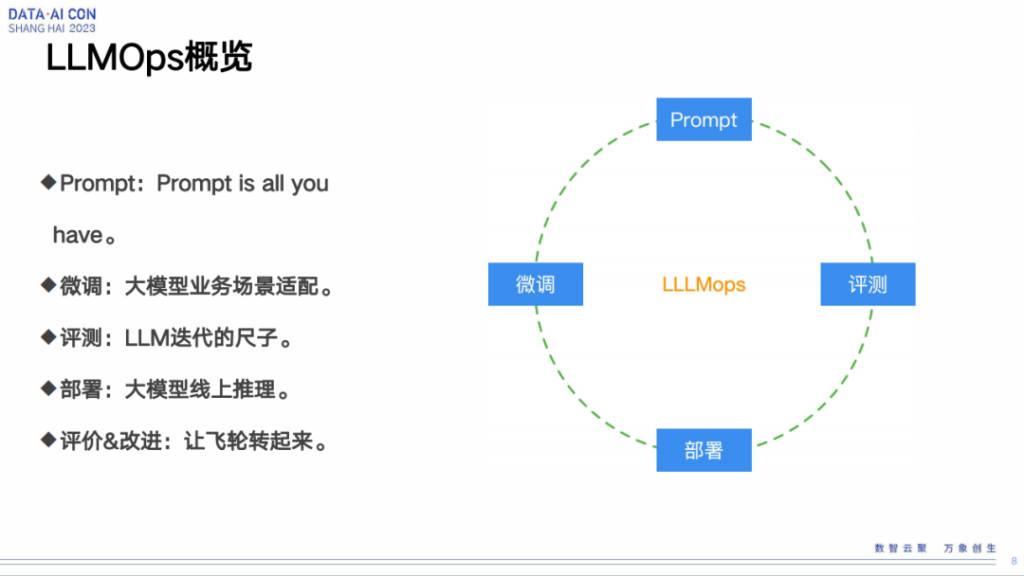
在大模型这块,我们总结了一下有这么几个环节,第一个就是prompt准备工作环节,说白了大模型至少大部分情况下都是基于prompt驱动的,所以第一步肯定是要把prompt做好。prompt做完之后就会到我们的评测环节,将我们的prompt输入到大模型里会有一些结果,然后我们针对性使用一些评测工具和策略来评估我们模型的情况怎么样。再到第三步,如果我们大模型效果还不错,我们就要放到线上去,那我们通过怎么样的手段放,然后怎么保证我们线上的模型一直可以很好的working。最后就是微调,到线上之后肯定还是会有,比如bad case,或者更多可以改善的地方。我们基于线上的反应数据,以及我们一些其他的前期的评测数据综合到一起,然后再反馈回来,重新去微调我们的大模型,达到逐益求精的过程。
最后就是有了这么几个阶段后,我们要想办法让这四个阶段能以一种自动化或者半自动化的形式正常转起来,其实后边我们会有一个比较完整的自动化的流程,这个我会在后面介绍。
LLMOps-Prompt案例

首先介绍一下prompt,prompt里面最重要的是prompt任务必须是明确的,也就是我们给出的指令必须要清晰的,没有一个歧义的,信息是比较完整的,比如这个是什么样的人,什么性别,然后要做什么样的事情,各个维度都是必须要相对完整的。再一个,我们交代它要处理的事情,比如如果是一个比较复杂的事情或者场景,那我们可以把它分拆成多个子任务。这边有一个case,是我们内部的一个图像生成case,我们给了一个prompt,然后输出了一个相应的图像,我们拿到这个图像之后会做到下游投放,服务于线上。
LLMOps-Prompt管理
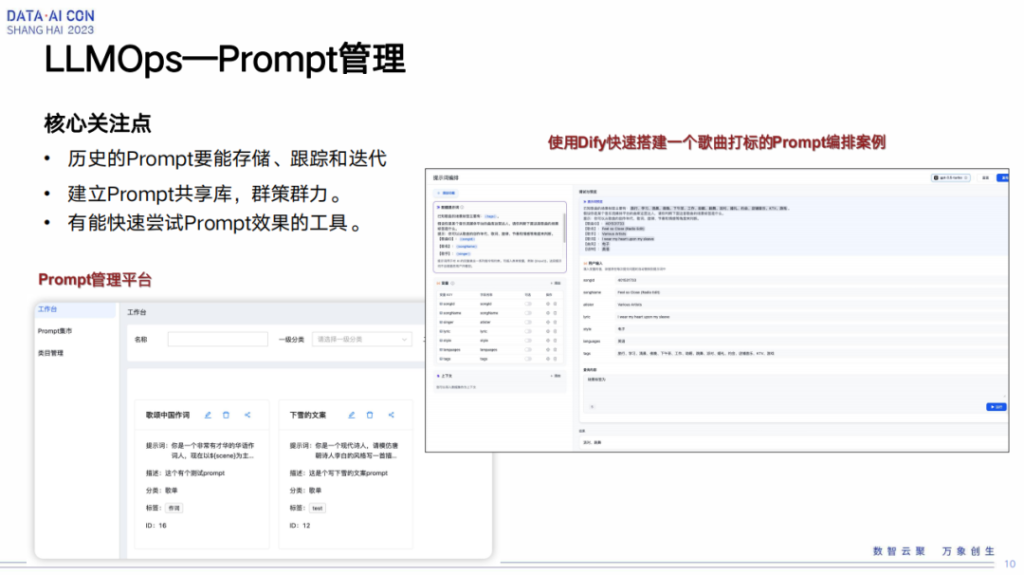
在平台侧prompt怎么管理,我们核心关注点是历史prompt要能够存下来,在我们需要的时候能看到或者说能够获取得到。
因为我们这边有不同的场景,那不同场景、不同人员,他们有自己的一些prompt的积累,所以我们希望能够将各个不同的场景或不同团队他们自己的prompt放到一个地方存储,然后通过共享的手段进行管理。再一个就是,有了这些prompt之后,能不能够让我们的大模型生成一些好的case。这块也需要一个比较好的手段,能够快速测试我们的prompt的质量。
但在具体实践过程中,我们使用了开源的Dify工具,然后集成到了我们平台里边,当然我们也做了一些自定义的手段,比如我们自己的一些模型能够加载到Dify里面来去做评测。
LLMOps—Prompt与知识库
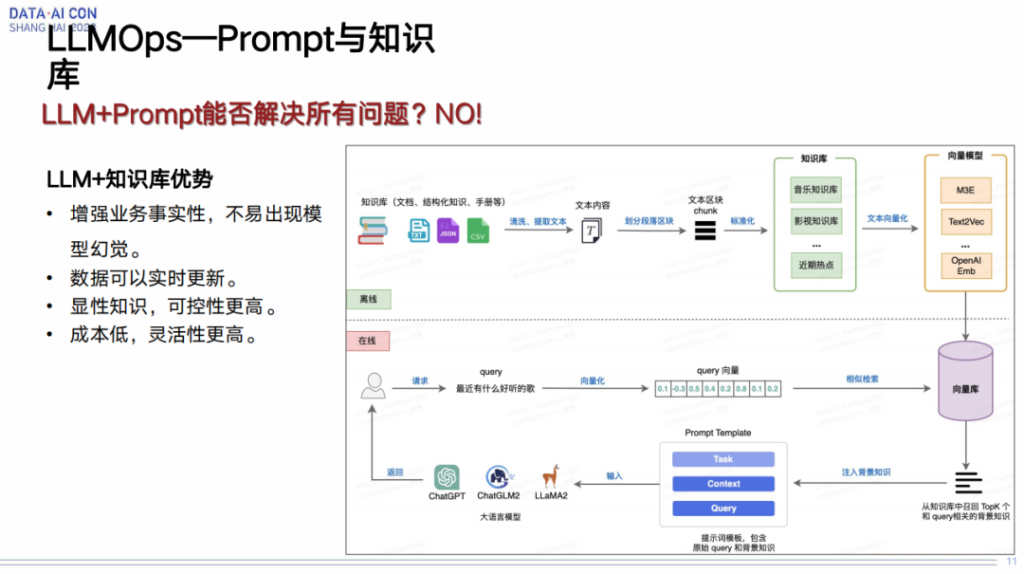
prompt在我们理解来说,它并不能解决所有的问题,因为在我们的业务场景里面会发现,尤其对于一些冷启动这种东西的时候,我们其实还是缺乏很多这种背景知识,所以单纯的一个prompt可能就是直接应用进来,不能达到我们业务所需要的效果。那怎么办呢?我们想的就是去引入一些外部的知识。
这里面第一点就是我们要怎么去构建知识库,能够解决我们线上出现的一些所谓的模型幻觉或者其他的一些问题。右边这个图有一个链路,上面这个链路是离线的,怎么构建我们知识库的一个链路。这里边有一些前期的数据清理的过程,然后标准化过程,再到最后会通过我们的向量引擎对知识库进行存储,以及能够通过向量算法快速获取。
再一个就是,我们真正在使用的时候,比如用户发起了一个请求,说了他的问题之后,我们首先会通过这个向量库进行一个相似检索,将相应的背景知识拿到之后,然后再跟用户输入的问题,以及相应的一些背景,比如他的年龄或者他的职位等等东西输入进来之后,组成最终的prompt,然后输入到我们的模型里面去,得到一个结果,大致的流程是这样的。整个流程虽然比较长,但是它最终效果还是不错的,确实能够帮助我们解决线上的一些问题。
LLMOps—评测

有了prompt之后,我们要怎么去评测大模型?刚刚提到大模型,尤其这种基础大模型或者比较宽泛领域的大模型,其实在我们特定的场景里面,它还是会有一些比较容易出问题的地方。那我们要怎么发现这些问题,以及怎么纠正这些问题?这个情况就涉及到大模型评测的流程。
LLMOps—人工评测
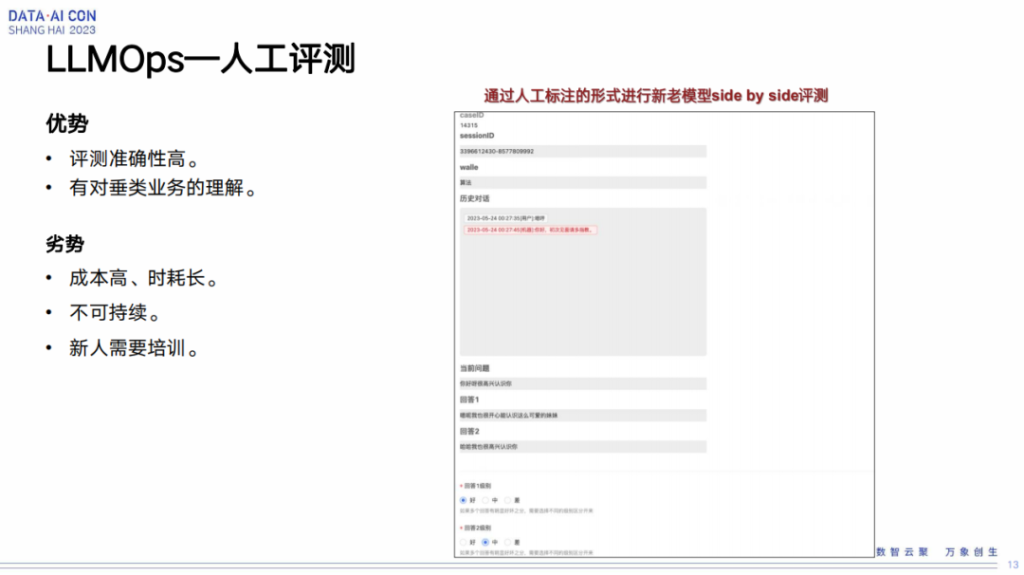
我们最开始是人工评测这么一个过程。人工评测就是我们自己有一个内部的平台,我们会在新的训练出的大模型以及线上的大模型两边输入同样的问题,得到两边的结果后,再做一个side by side评测。这个评测主要是以人工打标,看看这两个模型哪个效果好,哪个效果差。打标的数据我们也会存到内部的一个数据集里面去,方便于后续继续评测以及放到下一个迭代的时候能对下一个模型做微调。
这块它的一个优势,在于通过这种人工干预去评测,针对业务效果肯定是比较好的,但是成本相对比较高,另外可能一些新的人和新的运营同学进来之后,他们需要熟悉这么一个过程。我觉得最重要的还是在于成本,不仅是人力上的,还有流程上面的,这个评测不仅仅是策略怎么样,怎么样去评,还包括数据怎么组织、怎么获取、怎么呈现,然后用户拿到之后才去评,它的这个流程是非常非常长的。
LLMOps—自动评测
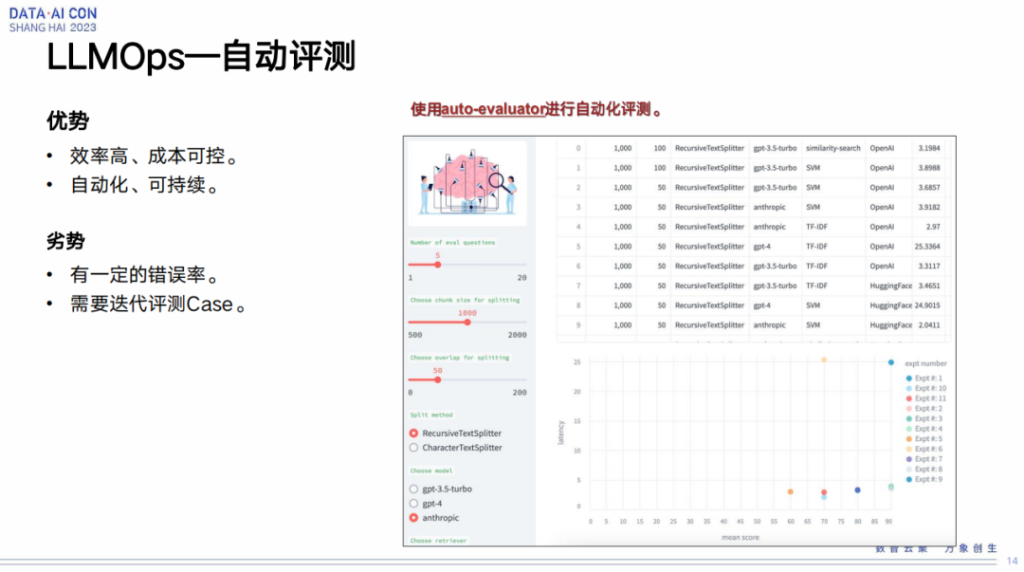
在自动评测这块,业界会有一些工具和方法做自动评测,我们就直接使用。它的优点就是很快速,完全通过机器取代人的标注。它的劣势就是会有很多错误,错误率比较高。
LLMOps—构建评测流程
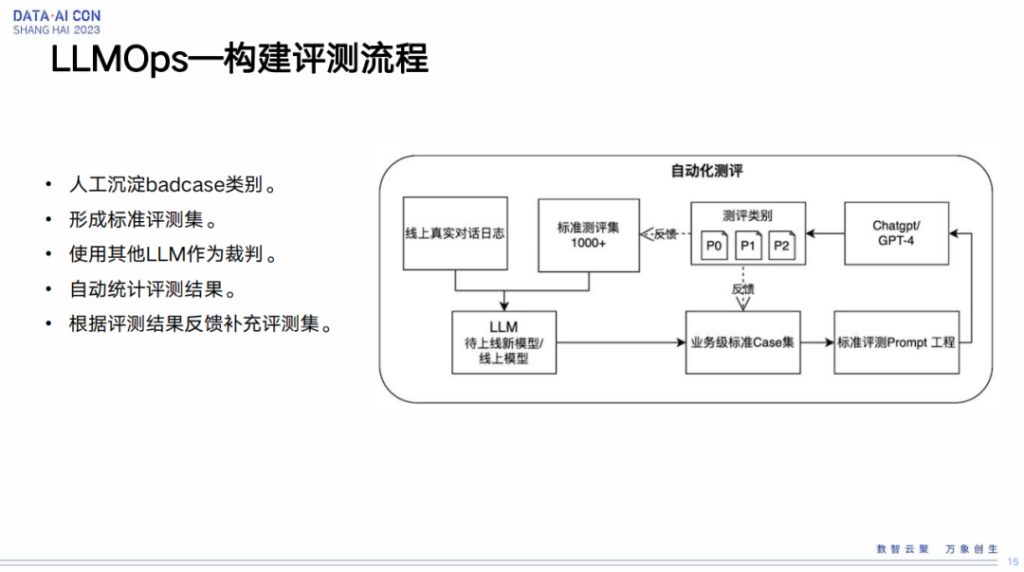
我们这块兼容两边的优点组成了我们的评测流程。它整体的流程是这样,第一步将现在部署在线上的大模型的用户真实日志拿到,第二步将评测集输入到刚训练的大模型里面,初步看看它的结果怎么样。这些都是我们自己内部迭代的大模型,那我们就想会不会有一个更好的大模型能够输出更好的结果,也就是怎么评判我们自己内部训练大模型的结构的好坏。所以这里我们引入了一个第三方的大模型,当然这个大模型也是有要求的,必须是能够相对比较准确,能够为大众所接受的相对比较好的模型,然后作为一个基准。最终我们会将三方的评测结果收录起来存下来,然后给到我们的算法人员,包括运营人员,去进行一个评测。
LLMOps—微调部署流程
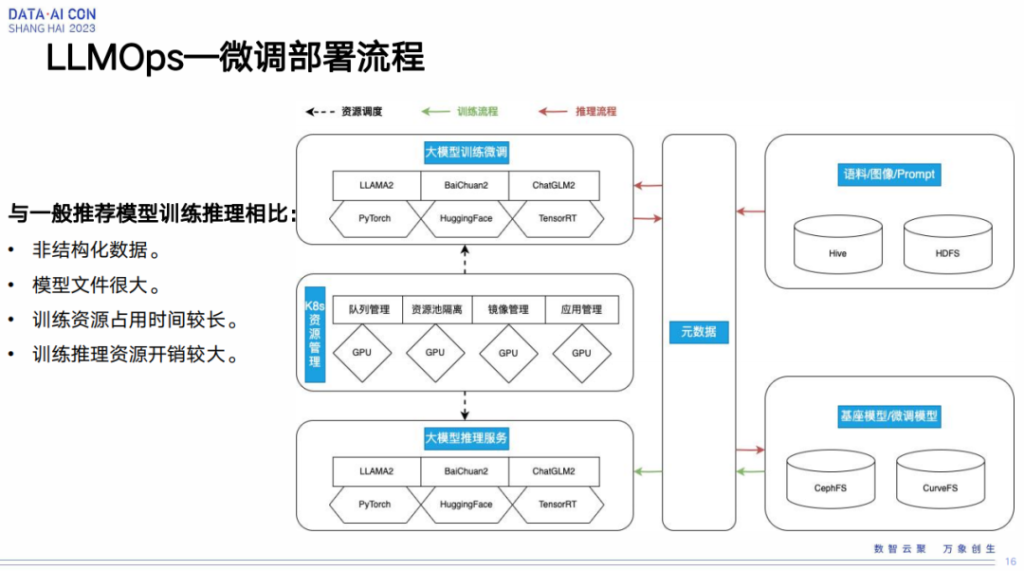
之后我讲一下怎么将我们的模型进行部署,以及怎么将部署到线上模型进行微调的迭代。这里我先讲一下整个微调部署的流程。可以看看右边这个图,最上面是大模型训练微调的步骤,最下面是大模型推理服务,中间这一层是我们的资源管理,右边是我们的数据存储,包括我们的语料/图像/prompt存储,还有是我们的基座模型,根据线上业务的反馈数据进行微调模型的存储介质。
这里跟我们一般的推广侧这种模型训练推理相比,他们有一些不同的地方。第一个不同的地方在于我们的这个大模型存储更多的可能是非结构化数据。推广搜这块相对来说还是有一些schema,也正因为如此我们才可以组织成特征存到类似于Hive表这种数据里面去。
第二是大模型的模型文件非常大,几十g都是很正常的情况,但是像推广搜这种模型,一般来说,也就是几个g的水平,这个就是会引来一个问题,对于推广搜我们的线上存储一般都是存到叫做对象存储这个文件系统里面去的,但是大模型就没办法存到对象存储里,因为如果存到里面去,那它无论是写入还是读取,都会花费很长的时间。我们内部还是决定存到像FS这种普通的文件系统里面,比如CephFS或者网易内部开源的CurveFS。
第三是训练这块资源的占用时间很长,也就是训练时间很长,但对于传统推广搜来说,训练的时间即使再复杂,半天可能基本就完了,但是大模型训练这块,数天甚至数周都是有可能的。那这块就会带来一个问题,因为我们资源其实是有限的,或者说我们必须要去控制资源成本,如果我们要把资源拿出来去训练大模型,那同时也要保障推广搜正常的这种训练任务。这一块涉及到队列管理,我们根据不同场景划分出不同队列,然后不同队列给到不同的场景去使用。
最后就是训练推理的资源开销比较大,这块推广搜目前大部分是用CPU去线上进行推理服务,但是大模型的线上推理服务,目前只能通过GPU的方式进行。刚才提到GPU的成本是比较高的,那我们怎么样能把这个成本尽可能的相对降低一下?我们的工作是应用了GPU的虚拟化,能够将一块GPU虚拟成多块GPU,然后每一块的GPU给到不同的推理服务用,其实就相当于将我们的一个GPU分摊到多个不同的推理服务,大概就这个过程。
LLMOps—部署
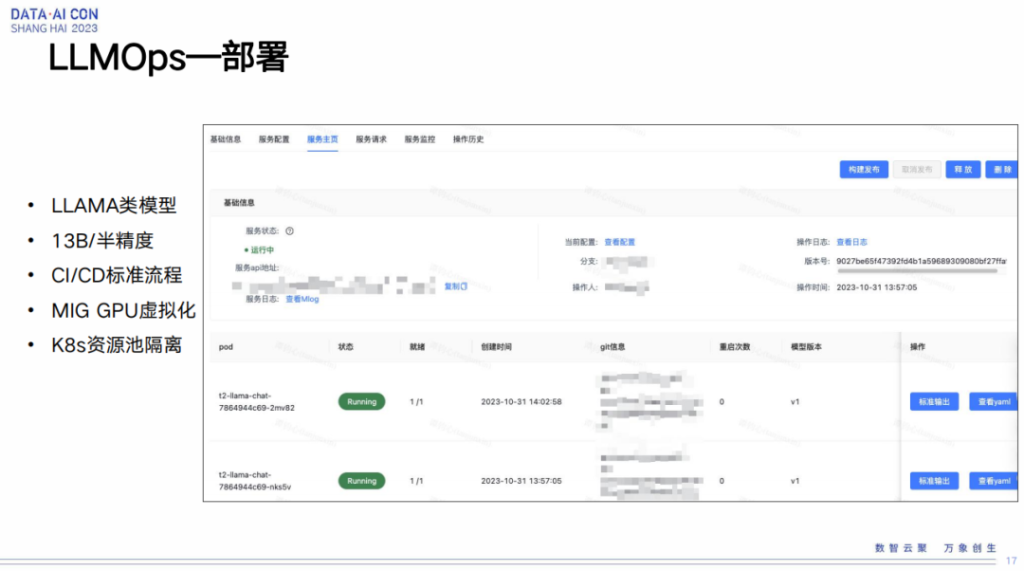
我再从平台层面上介绍一下我们部署的环节。因为我们之前有了普通的推广搜平台的建设经验,针对平台侧,我们可以很快速地复用这块的能力,比如部署的服务配置拉齐,包括监控配置,操作历史回滚等等操作其实都是可以完全复用的。
真正不同的地方,是刚才提到的大模型的推理服务对资源的占用是相对比较长的,利用率是比较低的。所以这块我们有一个操作,就是将我们的一块GPU虚拟化。我们目前使用的是英伟达GPU,它有一个特性是MIG,可以将一块GPU序列化成多个实例去进行使用,因此可以将我们整体GPU的利用率拉起来。
LLMOps—微调
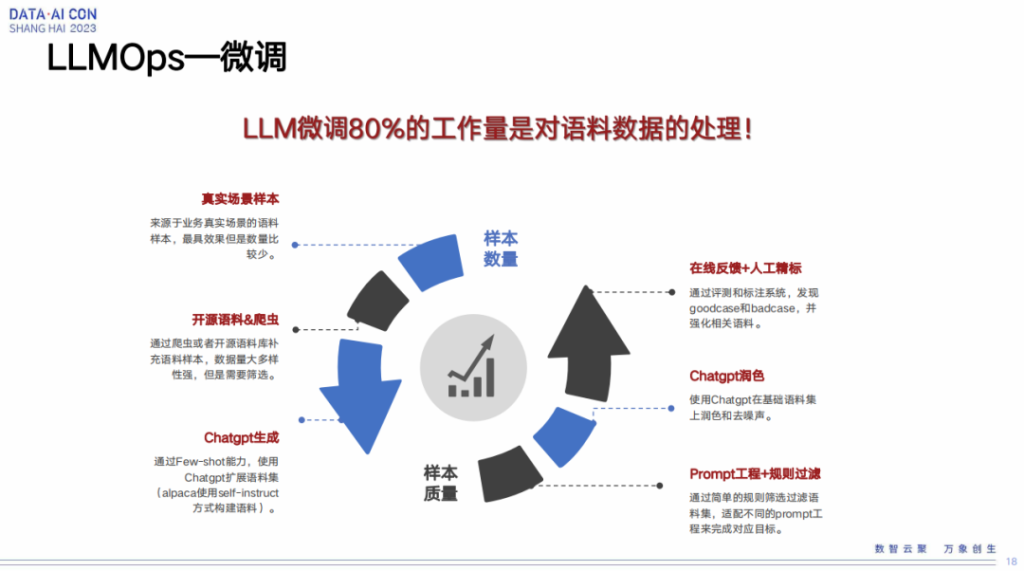
然后说一下大模型微调的情况,模型微调它的重点或者它的难点并不是我们怎么去训练大模型,而在于我们怎么为大模型训练做数据准备。这块要求有两个东西,一块是我们的样本质量,这是最重要的,再其次就是样本数量。
在样本质量这块,我们刚才提到有很多评测的工作,包括人工评测,打标,同时我们也会引入像ChatGPT或者其他反馈效果比较好的模型,做一些润色和其他的辅助的完善工作。
在样本数量这块,我们也必须要有一些保障。第一个是我们需要在拿到真实业务场景的数据后做一些清洗,同时尽可能将其他业务场景的数据补充进来。第二是外部开源那些数据,比如我们爬虫或者外部开源的一些语料,或者跟其他第三方的合作的数据都补充进来。第三是通过ChatGPT或者其他的类似模型,通过few-shot这种方式手段快速完善扩充Prompt数据或其他类型数据。
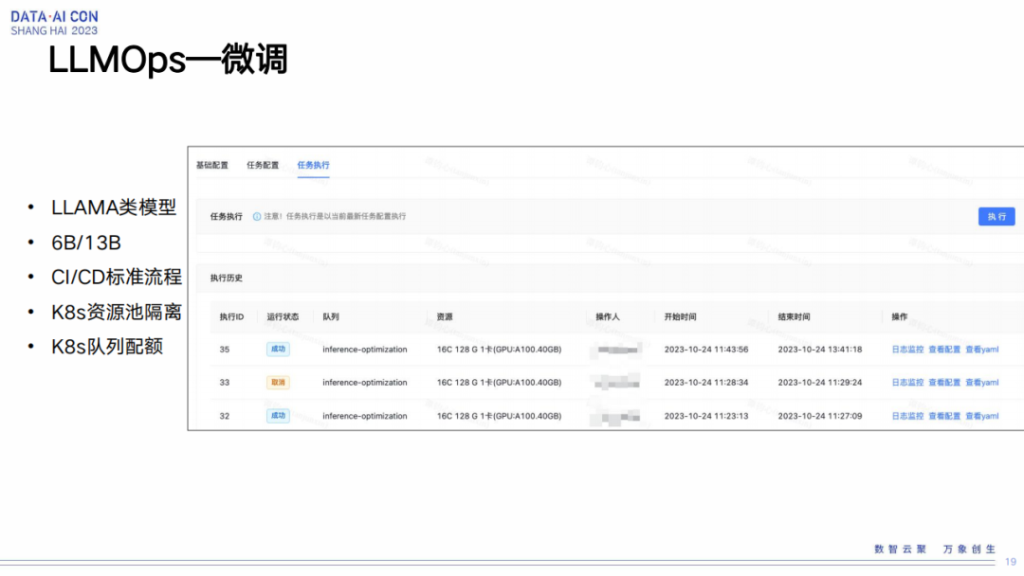
然后再介绍下微调在平台侧的一些东西,和推理服务侧这块类似,我们之前也有很多积累,在微调这块,平台可以很快速复用一些能力。我们之前有很多CI/CD的流程,CI/CD是模型开发的环境准备管控,模型开发的代码的管控。再一个刚才也提到大模型训练很占用资源,而且占用的时间比较长,我们为了不影响正常的推广搜模型的训练任务,我们针对资源划分出不同的队列,然后不同队列会有不同的配额。对大模型队列,我们会尽可能将较多的GPU 资源划到这个队列里,当然我们还会做一些稍微灵活的策略,能够给到不同场景中的团队,比较好的竞争这里面的资源情况。
LLMOps—评价&改进:让飞轮转起来
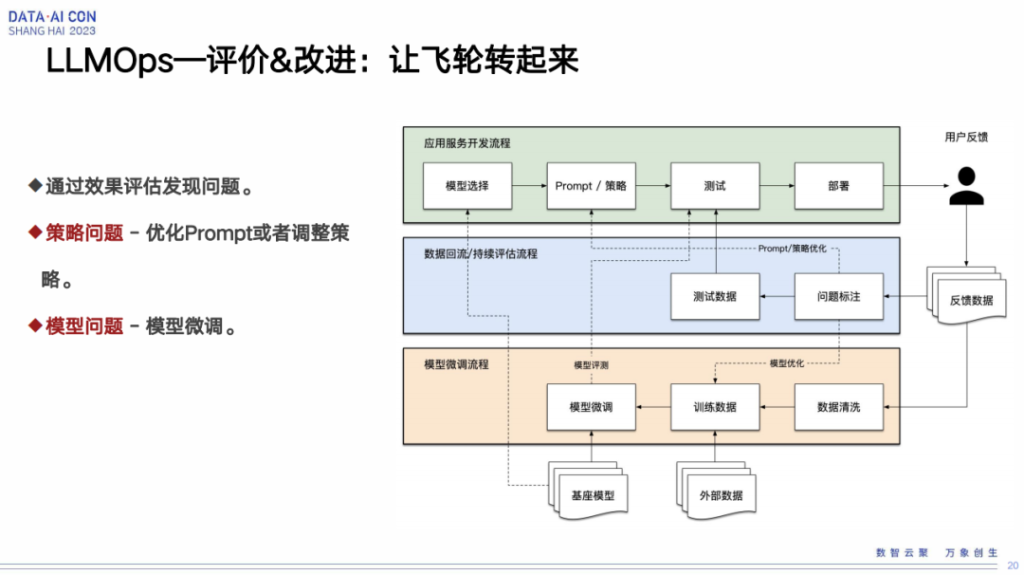
然后再说一下,当我们有了这么四个环节之后,怎么能够让这四个环节自动的run起来。右边这个图分为三块,第一块是我们整体的流程,中间这一块是我们怎么去评估、怎么去反馈,再下面这一块呢,是我们拿到评估反馈数据之后,怎么做模型的渲染微调。
这里面会涉及到几个点,第一个点是我们怎么样通过评估或者其他的手段去发现大模型里面的问题。第二是有这些问题之后我们怎么去解决。在我们的实际经验来看,会有两方面的问题。第一方面是策略上的问题,prompt或者其他的这种上游服务在进用户端的策略的调整。第二是模型层面的问题,当我们去评估一个模型,比如它有很多bad case之后,我们要通过人工干预、人工打标的方式得到一些比较好的数据集,然后再去进行模型微调,能够将无论是策略上的问题,还是模型上的问题,尽快的face掉,然后再应用到线上进行正常的业务迭代。
后续规划
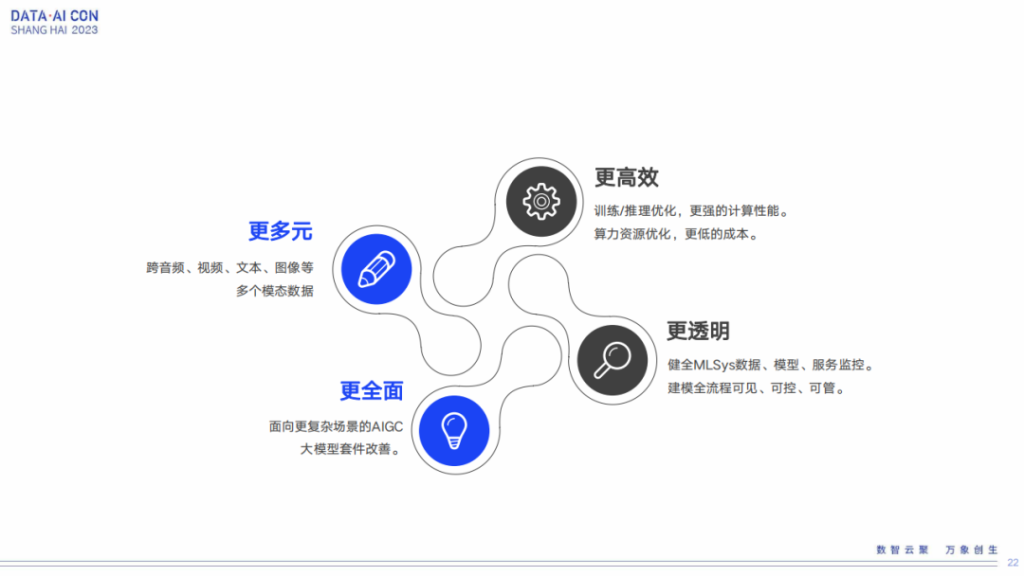
最后说一下我们后续的规划。最开始也说到我们这边工程化落地其实是在今年年中的时候才基本上铺开来的,时间还是比较短的,所以还是有很多东西需要去完善去补充的,这块主要分为四个方向。
第一个方向是希望能够有更多元的数据或者业务场景,能在我们的工程化落地上有比较好的完善。刚才我这些case大部分是针对文本或者图像的,我们还是希望能有更多的音频或者视频的相应场景能够跟我们平台结合下来。云音乐里面确实有很多音乐生成的场景,但是相对来说我们的做法还不是很标准,所以这块我们也会进行完善。
第二个是更全面。全面的意思类似于刚才提到的,我们会碰到比较复杂的大模型场景的应用。那我们怎么将这种复杂场景通过不同的组件化,或者其他的手段能得到较好的支持。
第三个是更高效。目前我们在利用率这块确实还有很多提升空间,那我们怎么将训练、推理的利用率打得更高,将我们整体的资源成本降下来。
第四个是更透明。对于我们这种算法人员或者运营人员,他们怎么能够快速使用这套流程解决他们的问题,同时让他们能够在一个地方看到流程里面的问题和每个步骤的情况,以及尤其是一些数据上的支撑。