
作者:刘树杰
编辑:麦吉哈
在Data & AI Con Shanghai 2023的“数据工程与大模型落地实践”分会场中,微软亚洲研究院首席研究经理刘树杰老师为我们带来了一场令人精彩回味的分享。他的演讲主题聚焦于「基于语音大模型的零样本学习的语音生成和翻译」,让我们获益良多,深入了解了许多有关这一领域的知识。
随着大语言模型在自然语言处理中的应用,语音大语言模型也逐渐受到更多关注。在本次分享中,刘树杰老师将介绍基于大语言模型的零样本语音合成技术,即VALL-E。VALL- E利用了大语言模型在上下文学习方面的能力,初步使用未知说话人的三秒录音作为音频提示,可以生成高质量的个性化语音。此外,刘树杰老师他们还进一步将VALL-E扩展为VALL- E X,实现了高质量的跨语言语音合成,显着解决了外语口音的问题。通过利用大语言模型技术,进一步的将VALL-E (X)从语音合成任务聚类了语音识别和机器翻译,并使用一个统一的模型来实现语音识别、翻译和合成三个任务,从而可以实现高质量的基于单一模型的零样本级联式语音到语音的翻译。
前言
微软实际上是从去年10 月初就开始用language MOS来做语音合成,我这儿就简单介绍一下一些相关工作。
近期GPT 特别火,large language model也用在各个地方,如果我们把语音的数据转换成离散的字符串,那是不是就可以构建一个语音版的large language model?
要构建一个语音的large language model,我们需要解决三个事情:
- 我们如何把语音转成离散两串;
- 我们能用什么样的数据去构建这么一个模型;
- 这个模型跟正常的large language model有什么区别。
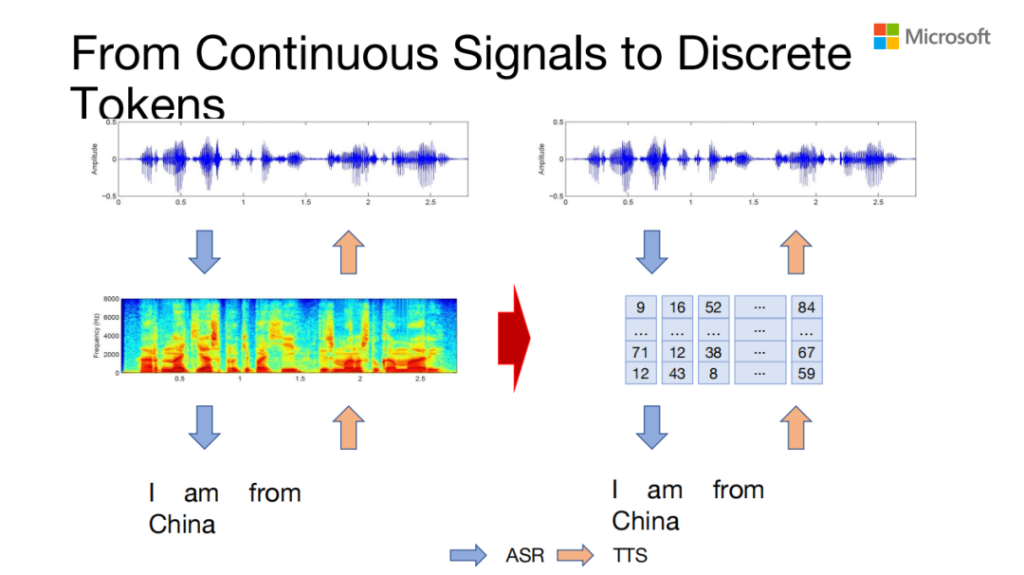
上面展示的是原来的语音处理,输入一个字符串,然后转成梅尔普,最后再转成view。它中间表示的是梅尔普,是一串向量,我们要把它转成离散的一个字符串。
How to Convert Speech to Tokens?
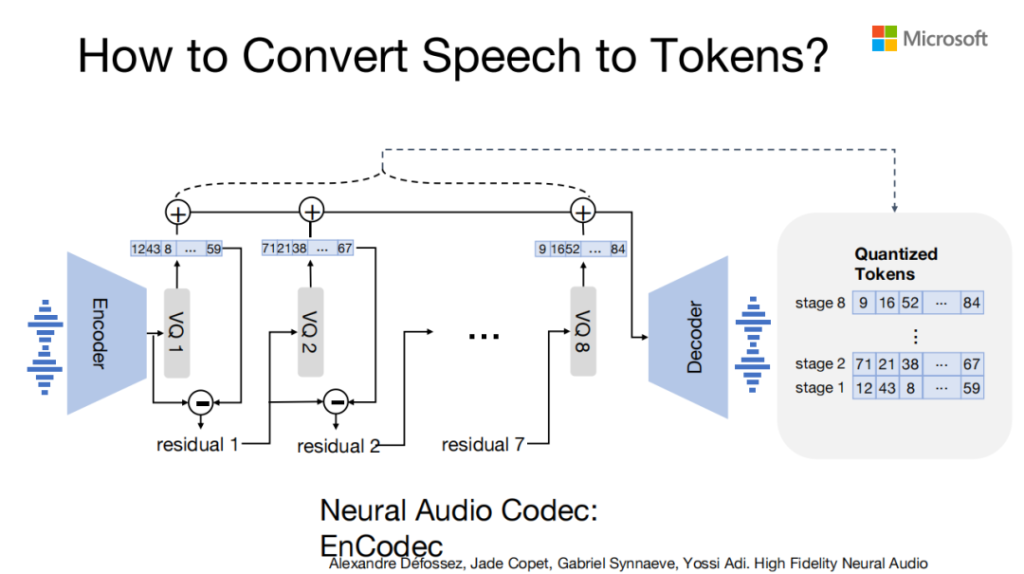
我们把语音的信号转换成离散信号用的是Neural的Audio Codec,给定左边语音一个输入,然后经过一次encode,encode完之后每一帧会有一个HIDDEN state,它有个向量,然后给这个向量先做一次VQ,即拿HIDDEN state跟code book里的code embedding比找个最近的,然后用hidden state减去code embedding得到第一个code,之后用减去的那个再做一次VQ,然后得到第二个code,依次往下减。
它之所以叫residual ,是因为它的第一层的第一个code包含了向量最多的信息,然后依次越来越少,所以我们实际上是有8层的,每一帧有8个code,这8个code对应的embedding加起来之后再经过一个decoder,把语音的信号还原出来。经过residual 的VK、V1之后,给定一个音频的输入,我们就可以得到一串离散的向量。
Speech Data
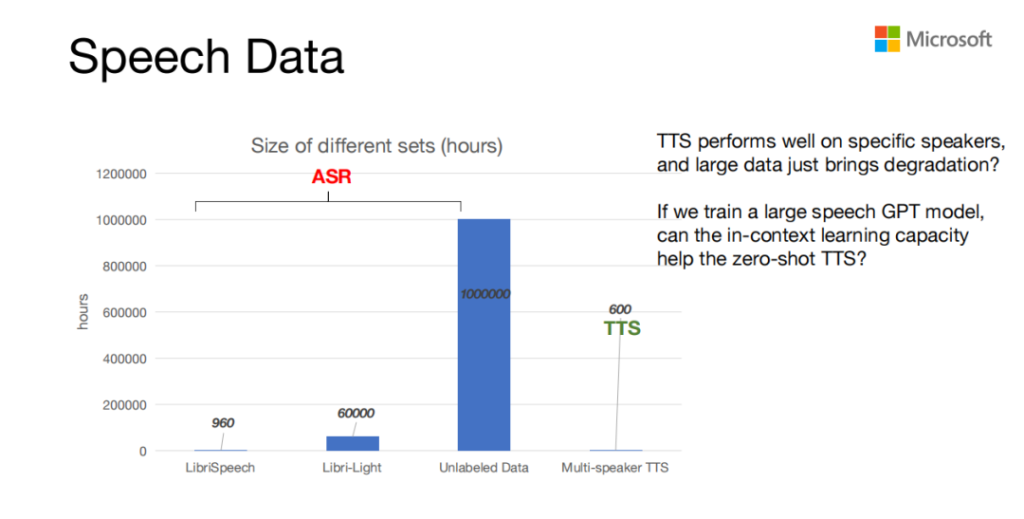
语音数据用的是语音处理里ASR和TTS的数据。ASR中一些小的数据,大家可能用的都是960小时的LibriSpeech,还有没有标注的Libri-Light,大概6万小时。TTS数据需要音质非常高,往往需要在录音棚里采集,cost比较大,所以量级相对比较小,一般都不会超过600个小时。
以前的TTS因为是在录音棚里采集,数据比较小,所以在特定的speaker上表现的就比较好。但如果迁移到其他的speaker,它的音质可能就会下降很多。而大规模的ASR的data往往对TTS的model改进比较有限。那我们就想如果我们可以用大规模的ASR的data来串一个speech的GPT model,那speech GPT model的in-context learning的能力能不能来改进Zero-shot或者Zero-shot TTS 的性能。
Speech Model Size
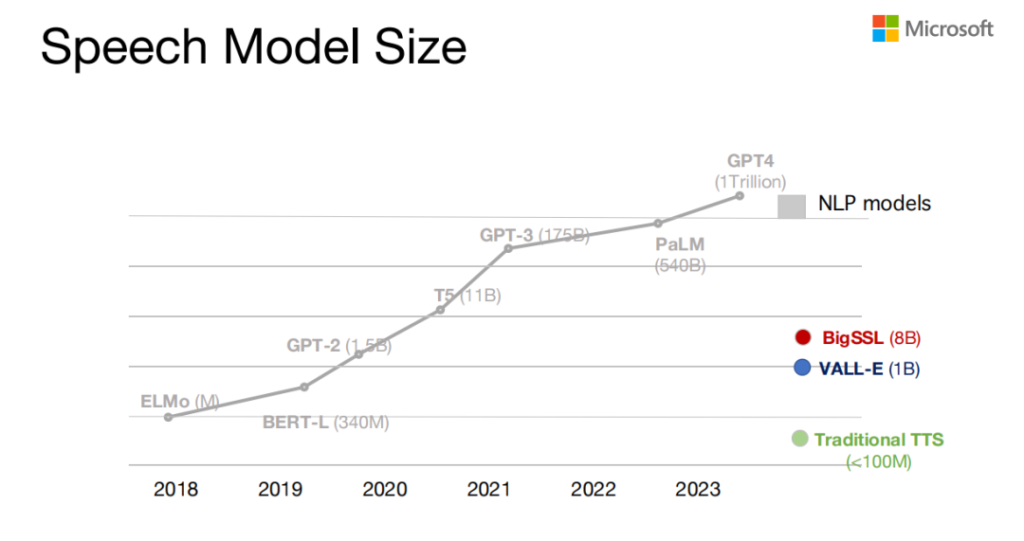
从model size来说,像NLP models的GPT4大概有一个trillion的parameter。但是对于speech的model来说,最大的ASR model是BigSSL ,大概是八个billion,传统的TTS model大概也只有小于100M的model size。我们想构造的model,当时设想的是一个billion左右。
Build a Speech Version of GPT:the first try

这是我们当时整个task的构建,我们想把speech信号转成离散信号,用了neural codec做Encodec;然后用大规模的且多说话人和多让的数据,用了Libri-Light6万小时的数据;然后我们用large Transformer structure去解决长尾的问题,也就是voice cloning,它可以来做 TTS 或者语音到语音的机器翻译。
VALL-E:Neural Codec Language Modeling
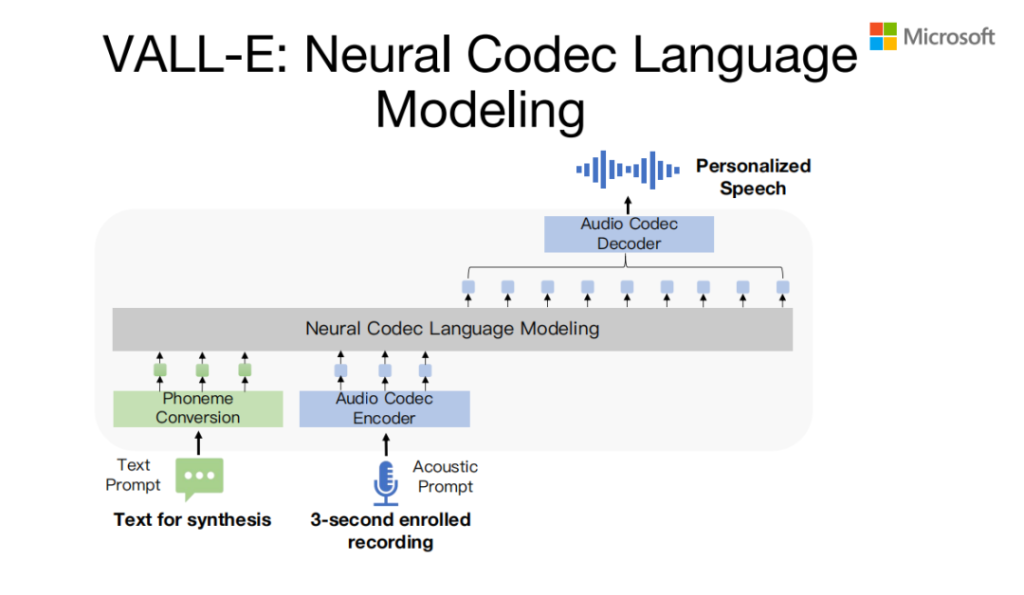
VALL-E model其实是一个Neural Codec的Language modeling,前面是一个文本串,后边是一个语音转换成之后的codec 串,在influence的时候输入的test prompt是两个句子的prompt,两个句子的test,语音prompt第一个句子对应的语音,然后后边继续生成,通过large language model来生成第二个句子的codec,然后基于第二个句子codec code,基于codec 的Decoder,把音频信号还原出来。整个的VALL-E model 分两部分,这儿说的是一个自回归的生成思路。
Stage1:AR Transformer
因为前面介绍过incodec,它每一帧有8个code,那就是如果我们通过这种自回归的方式,它只能生成第一个code,就是每帧只能生成一个code,那剩下的7个code,我们会有一个NAR的模型来做。
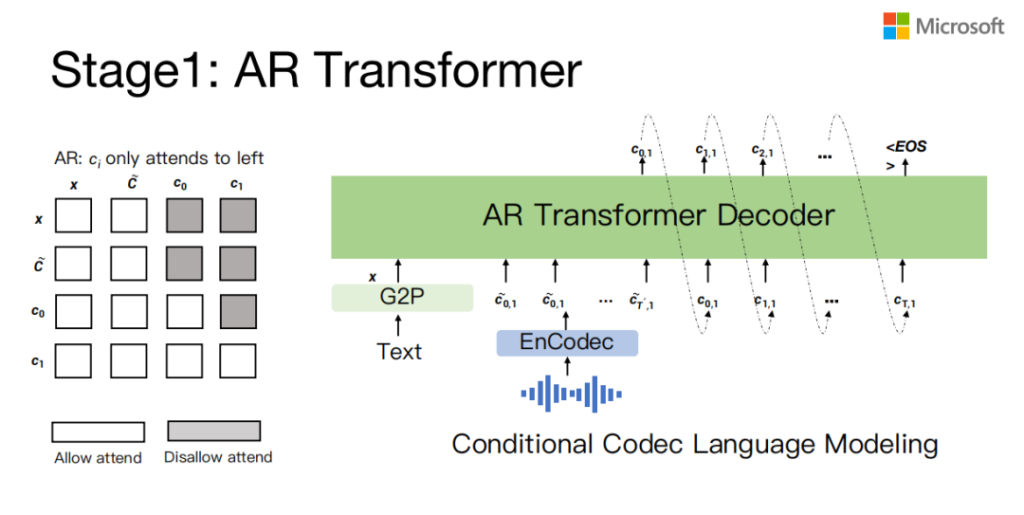
这先介绍一下AR模型, AR模型就是在训练的时候,它有test,有speech prompt来生成target prompt,然后mask的时候只是自回归到mask target speech对应的Codec,这是自回归decode能力的一个model。
Stage2:NAR Transformer
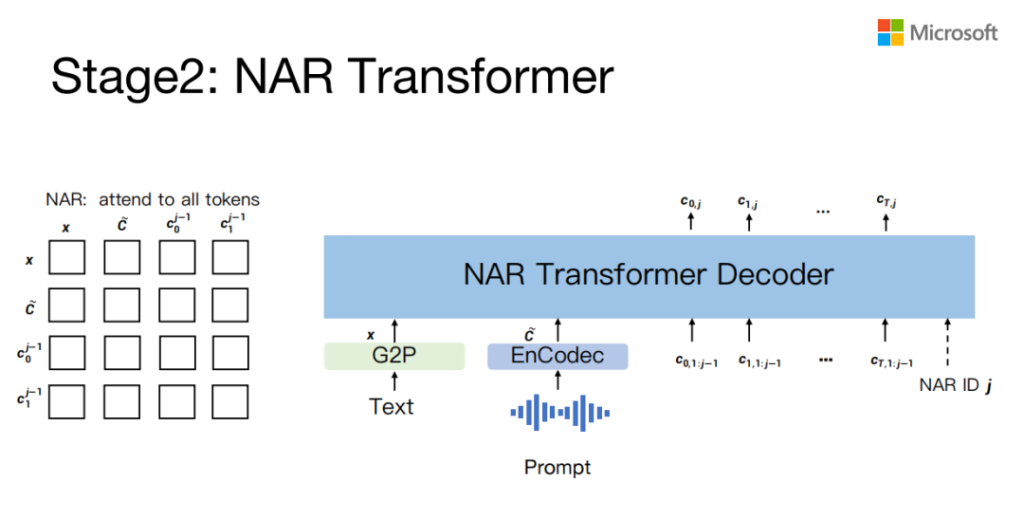
非自回归的模型,它的网络结构跟自回归模型是一样的,训练的时候唯一不一样的地方在于mask机制不一样。回归的因为你不能看到未来,所以你要把未来的信息mask掉,但是NAR的时候是没有任何mask的,它的输入是前边若干个code,你如果要生成第三层,就要把前两层生成的code,然后它对应的embedding加起来都输入,然后来预测第三层,你要生成第四层的话,就把前三层的加起来。
Experiment Setting

具体的实验的setting, AR和NAR这两个模型都是用12层的1024的hidden states,然后Data是用的Libri-Light ,6万小时7000个speaker,然后我们是在16个32G的V100上training的,训了5000左右。
具体的Latency ,在A100上要生成1秒的speech大概需要0.5秒,如果在V100上大概就是1: 1 ,生成1秒的speech就需要1秒的时间。
在这提一下,这个训练数据对训练序列实际上是有特殊的要求,它跟原来的TTS训练不一样的地方是它需要说话人尽可能的多,见过足够多的说话人之后才能模拟他的声音,还有它需要见过的声音的韵律尽可能的丰富。所以这也是我们为什么用Libri-Light的数据的原因,对背景音也希望尽可能的干净一些。
Experiment Results(LibriSpeech)
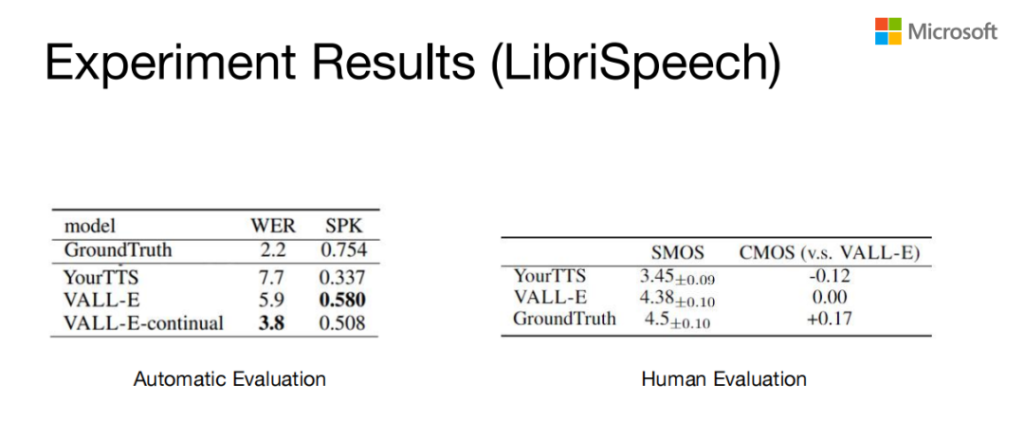
上面是VALL-E在自动评价和人工评价跟其他模型的一个比较。我们当时是跟YourTTS 比的,YourTTS算是学术界比较好的一个model。然后VALL-E无论是在WER还是在speak similarity上都比baseline要好一些。我们speak similarity是基于一个speech speaker verification的model去打的。
右边是人工评价的结果,SMOS是speaker的MOS,CMOS是拿VALL-E跟YourTTS和GroundTruth进行比较,然后从speaker来看,其实VALL-E比YourTTS要好很多,然后跟GroundTruth实际上已经比较接近了。从MOS上来说,VALL-E的结果介于YourTTS和GroundTruth之间,离GroundTruth还是有一定的距离。
Speech Diversity
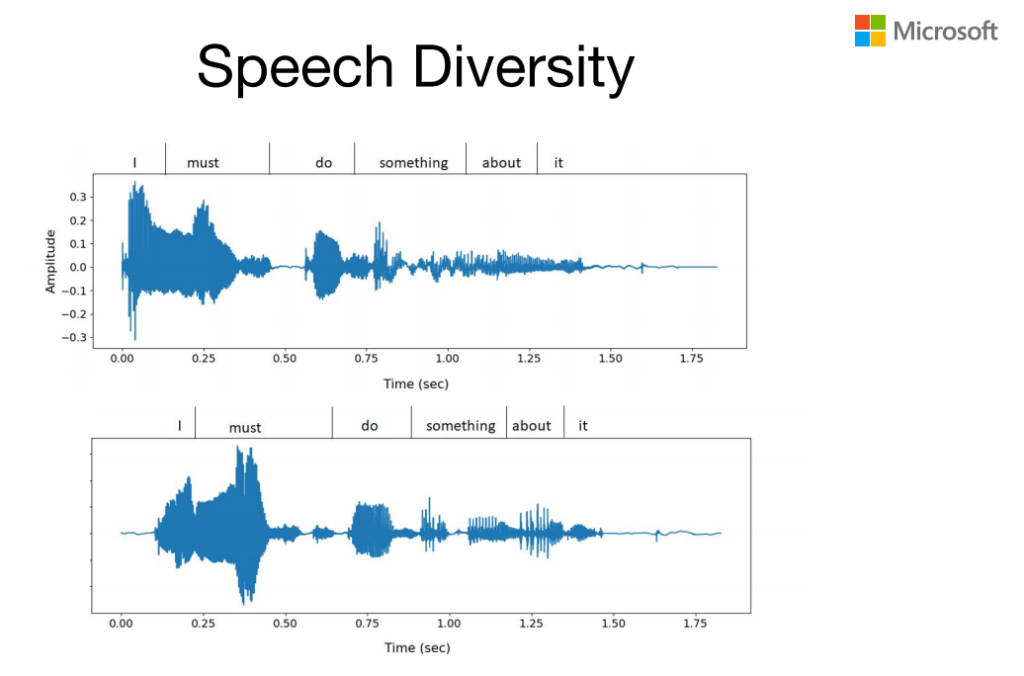
基于Codec的或者基于离散的字符的这种模型,它比较好的地方在于表现力特别好,也就是给定一个文本的输入,它可以以不同的韵律读出来,比如上面这个同样读这个I must do something about it。第一个的重音是在I上,而第二个重音是在must上,也就是它可以用不同的重音或不同的调来读同样的一个输入。
Zero-shot TTS Examples
下面是一个例子,你给定VALL-E一个什么样的prompt,那个 prompt 里边有什么样的emotion,它可以克隆这个 speaker 的音色的同时也克隆他的emotion。比如说这个,它是一个非常生气的一个prompt:
Audio Book for Reid Hoffman

Reid Hoffman写了一本书叫《Impromptu》,他是跟GPT合作,实际上就是有些文字是GPT生成的,有些是他写的,以这种方式写了一本书,然后我们用VALL-E帮他生成了有声书。
这有两个例子,一个是他自己读的,一个是我们生成的,我们可以听一下:
这里第一个是我们的声音,第二个是他的声音。他本人的声音是有非常强的一个表现力,这一块 TTS 还是做的没那么好,因为现在TTS的韵律还是依赖于prompt。
VALL-E X:Cross-Lingual Neural Codec Language Model
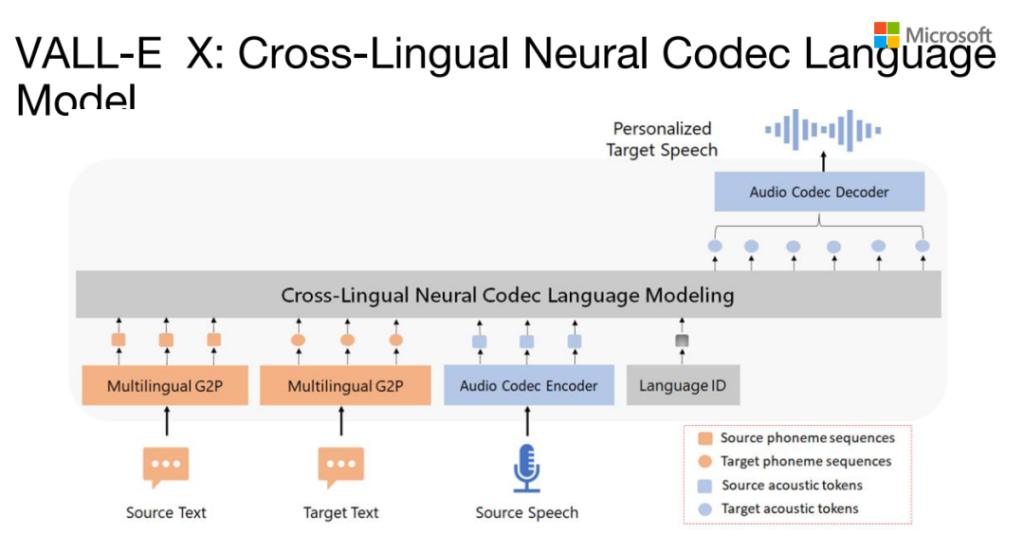
我们对VALL-E继续进行扩展,做了一个Cross-Lingual的VALL-E版本。原来第一个版本只支持英文,现在这个版本我们做了中和英,然后我们内部也有其他一些语言的实现。为了让VALL-E支持其他的一些语言,我们中间加了一个language ID。它其它的部分跟VALL-E是比较相似的,在inference的时候,第一个是source language test,第二个是target language test,然后再有source speech,来生成target speech。
VALL-E X Inference
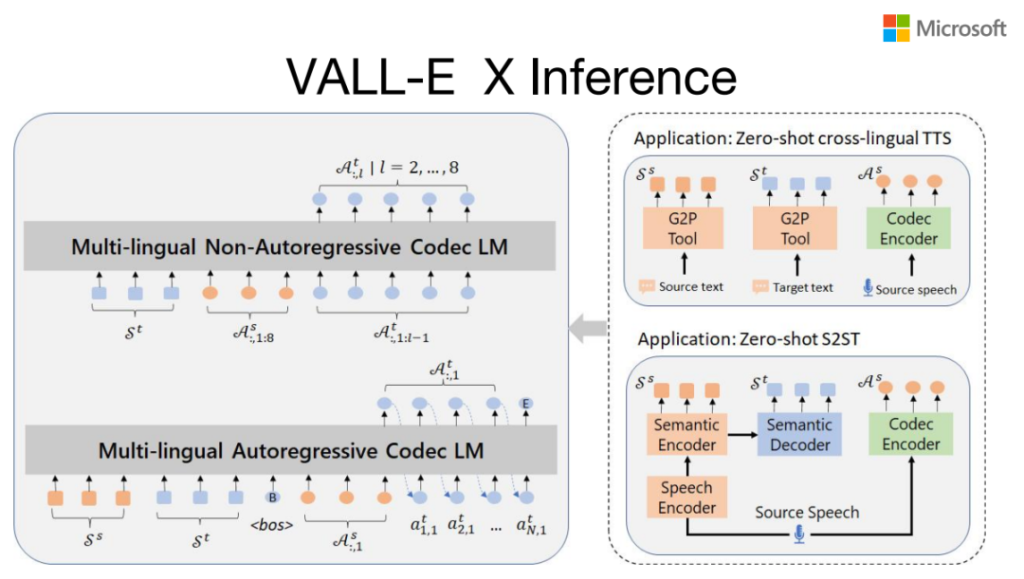
Cross-Lingual的VALL-E可以支持Zero-shot cross-lingual TTS,以及可以支持Zero-shot的语音到语音的翻译。
Experiment Results(Cross-Lingual TTS)
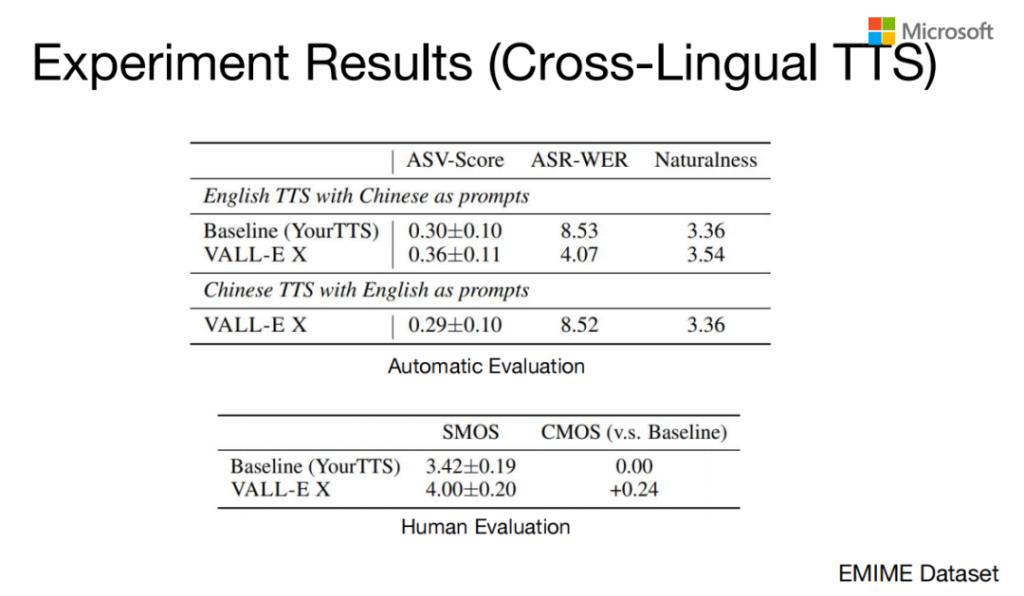
这是具体的一个实验结果,我们拿VALL-E X跟YourTTS做了一个比较,测了一下它的ASV,然后生成语音做出ASR之后再来算WER,还有它的Naturalness来测自然流畅的程度。下边那个是跟人比较的结果。从这些结果来看,VALL-E X比原来的方法明显要好很多。
Experiment Results(Language ID)
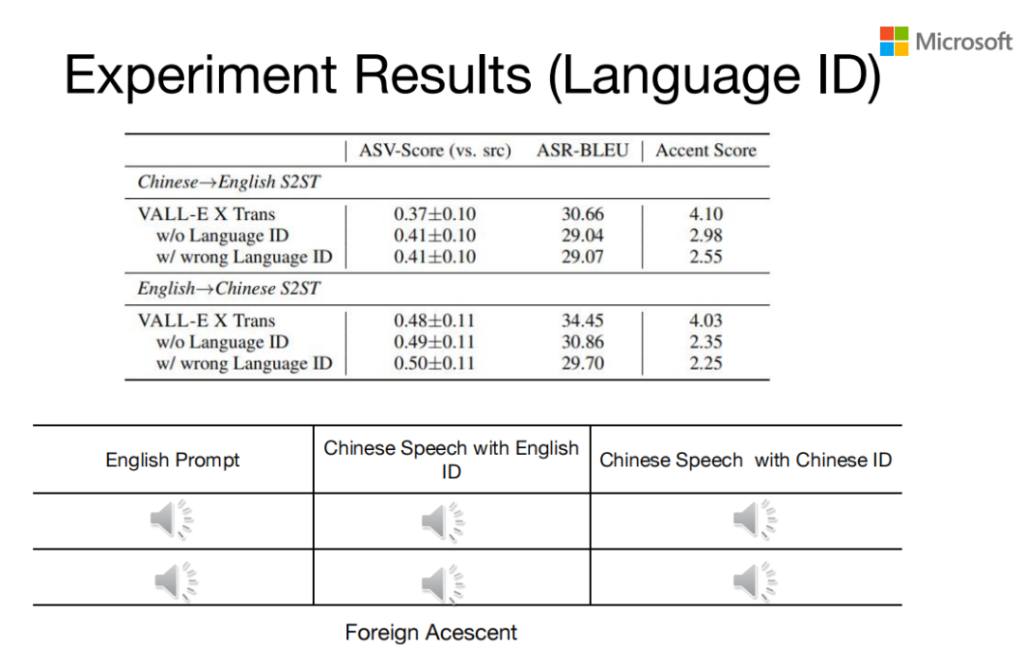
前面提到我们加了一个Language ID,我们发现这个Language ID实际上是非常重要的。Cross-Lingual TTS有一个很大的问题就是外国口音,这个问题通过Language ID可以得到非常好的一个改善。
Azure AI Speech launches Personal Voice inpreview
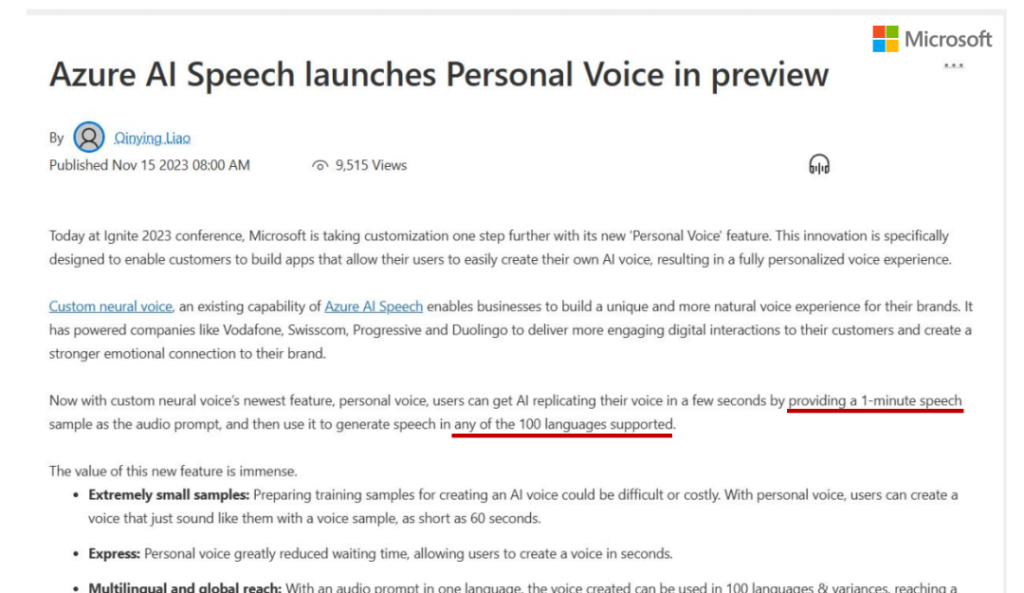
微软前几天上线了personal voice cloning。我们原来的系统说是可以只要给定3 秒的speech prompt,它就可以刻录你的声音,但实际上你给它的speech prompt越长,它生成的音色就越像。所以这个上线的系统,默认你要输入一分钟的speech来做prompt,它支持100种语言Cross-Lingual的Zero-shot TTS的生成。这个是public Preview,如果要试的话需要注册一下。
Speech LLM
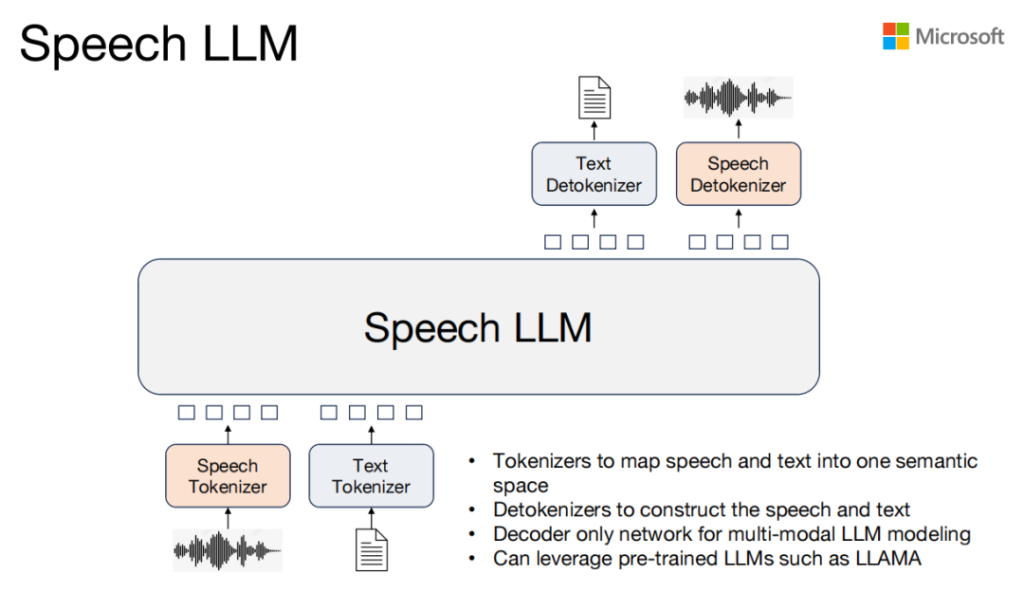
我们前面都是用Large language model来做语音生成,实际上我们想做的事情不止是做语音生成,我们希望能做所有的speech task,我们希望能把speech和test映射到同一个semantic space token,然后用large language model基于这个token来做一个模型,这个模型可以使用已经创建好的一些Large language model,比如LLM,这是我们想继续做的一个事情。
VioLA:A Unified Model for ASR ,MT,TTS and ST
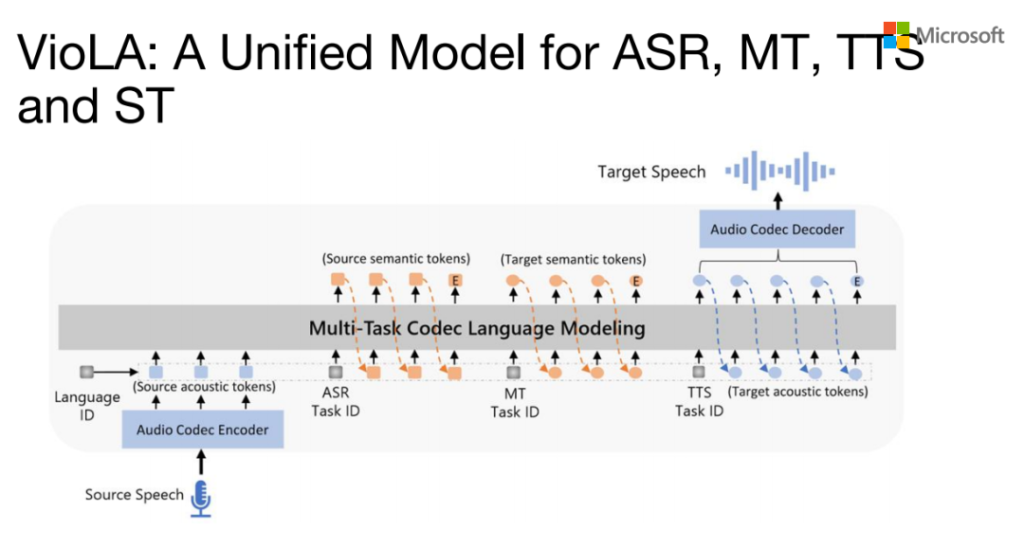
基于上面的思路我们就做了VioLA,它是一个统一的模型,可以支持ASR、 MT和TTS,同样也可以支持语音的翻译,它实际上就是一个multitask decode的language model。比如你要做ASR,speech输入,有个language ID,然后input,你就可以predict它的ASR结果。同样的也可以做一个MT的task,以及前面介绍的TTS task。
Summary

我们的VALL-E跟原来的那些模型相比,在Zero-short task上已经明显的好,跟GroundTruth在speak similarity已经接近了,VoiLA把VALL-E和VALL-E X扩展到了ASR,MT和TTS task。
我们觉得基于Codec这种底部的large language model可能是一个非常有前途的研究方向。其实现在无论是国内还是国外,都有很多后续的工作在做。我们也在想有没有可能把视频、video或者语音,统一映射到一个离散空间,来训一个统一的large language model 。