"Hi Sir, please play Mozart's piano music", "Okay, which song do you want to play?"... Nowadays, voice assistants have entered thousands of households, and almost all of them are equipped with mobile phones, tablets or smart speakers. A voice assistant that is always on call. But how much vocabulary do these fluent voice assistants have? Does does their language learning need to start from ABC just like humans do? The answer is that they don't need to accumulate gradually, but through a library of pronunciation dictionaries, which covers all the voices that the voice assistant can recognize.
The pronunciation dictionary (Lexicon) contains the mapping from words (Words) to phonemes (Phones), which is used to connect the acoustic model and the language model. The pronunciation dictionary contains a collection of words that the system can handle, with their pronunciations marked. The relationship between it and other modules of speech recognition is as follows: the mapping relationship between the modeling unit of the acoustic model and the modeling unit of the language model is obtained through the pronunciation dictionary, so as to connect the acoustic model and the language model to form a search state space, using Decoding in the decoder. Our recognition target is a word sequence (the result of sentence segmentation), and each word is converted from a pre-constructed pronunciation dictionary (Lexicon) to a corresponding phoneme sequence (Chinese phonemes usually refer to the initials and finals in Pinyin), that is, the word sequence Convert to phoneme sequence.
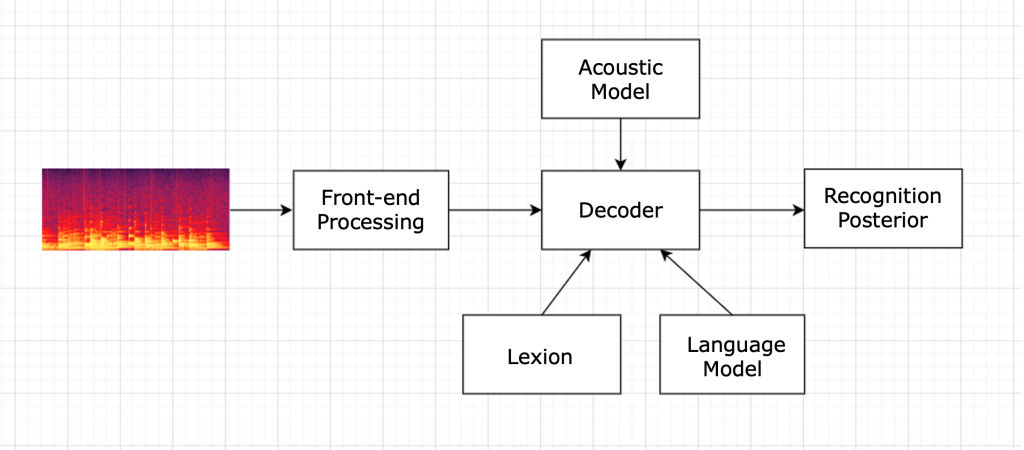
In a speech recognition system, the larger the amount of data contained in the pronunciation dictionary, the better the effect of improving the accuracy of speech recognition. Pronunciation dictionaries and languages correspond to each other, and a pronunciation dictionary needs to be prepared for each language. When new words are generated, these words and corresponding phonetic symbols can be added to continuously expand the size of the dictionary. Therefore, vocabulary size, phonetic transcription and proofreading accuracy are important criteria to measure the quality of the pronunciation dictionary.
At present, many pronunciation dictionaries are not very accurate because they are generated by themselves, which will affect the performance of the speech recognition system. How to collect a large number of accurate and comprehensive pronunciation dictionaries has become another problem in the field of speech. At the same time, since the collection, labeling, and cleaning of pronunciation dictionaries require professional linguists and acousticians to control, there is very little open source pronunciation dictionary corpus, and professional data companies are required to provide more support and collection of pronunciation dictionary data resources.
At present, Magic Data has established a mature pronunciation dictionary construction process and accumulated profound basic research results of phonetic linguistics. There are pronunciation dictionaries of various languages and dialects, including Mandarin, French, Italian, Japanese and many others. Each pronunciation dictionary has been comprehensively collected, meticulously annotated, and each word in it has been manually proofread. It is a set of high-quality pronunciation dictionaries. These pronunciation dictionaries can be used to build larger, more comprehensive, and more accurate pronunciation dictionaries, thereby improving the accuracy of speech recognition.
Try Magic Data open-source pronunciation dictionary at MagicHub.