

Despite repeated claims of “near-human” performance on standard benchmarks, automatic speech recognition (ASR) systems continue to struggle in real-world voice agent scenarios.
The issue is no longer just recognition accuracy. Under realistic conditions, models frequently exhibit instability, degradation, and even semantic hallucinations—generating plausible but incorrect content that was never spoken.
Recent work, including the WildASR benchmark, highlights a fundamental limitation in how ASR is evaluated today: most benchmarks rely on in-domain data and average error rates, which fail to capture how systems behave under real-world distribution shifts.
WildASR addresses this gap by introducing a diagnostic benchmark built entirely on real human speech across four languages (English, Chinese, Japanese, and Korean). Rather than reporting a single accuracy metric, it systematically analyzes robustness across three dimensions: environmental degradation, demographic shift, and linguistic diversity.
A unified evaluation of seven mainstream ASR systems—including Whisper, GPT-4o Transcribe, Gemini, and Qwen2-Audio—reveals a clear pattern: performance is fragmented, robustness does not transfer across conditions, and failure cases are far more severe than benchmark results suggest.
I. ASR Appears Mature—But Hidden Risks Remain
Over the past decade, ASR has made significant progress, driven by neural architectures and large-scale datasets. Benchmarks such as LibriSpeech and FLEURS report word error rates (WER) below 5%, often interpreted as near-human performance.
However, these results do not hold in real-world deployments.
Performance drops sharply under conditions such as:
- telephony compression
- far-field recording
- accented speech
- children and elderly voices
- code-switching
- truncated inputs
More importantly, the nature of ASR usage has changed.
ASR is no longer just a transcription tool—it increasingly acts as the entry point for downstream systems, triggering actions, queries, and decisions. As a result, errors are no longer isolated—they propagate.
Yet current evaluation frameworks:
- focus on average WER rather than failure modes
- lack visibility into specific breakdown conditions
- do not capture cross-language robustness
- provide limited guidance for real-world deployment
WildASR is designed to make these failure modes visible.
II. Key Contributions
- A real-speech diagnostic benchmark
Covering English, Chinese, Japanese, and Korean, with explicit modeling of out-of-distribution (OOD) conditions - A unified evaluation protocol
Comparing seven mainstream ASR systems under identical conditions - Practical diagnostic tools
- P90 inflection analysis
- Prompt sensitivity profiling
- Hallucination Error Rate (HER)
III. WildASR Design: Real Data, Not Synthetic Proxies
A key design choice in WildASR is the exclusive use of real human speech.
Unlike synthetic datasets, which often smooth out variability, real speech preserves hesitation, disfluency, pronunciation variation, and interaction dynamics—factors that significantly impact model behavior.
The dataset is constructed through a controlled pipeline:
- Data collection
- Speaker filtering
- Quality filtering
- Normalization
- Acoustic augmentation
- Manual truncation and alignment
- Human verification
Robustness is then evaluated across three axes:
- Environmental degradation (where)
- Demographic shift (who)
- Linguistic diversity (what)
IV. Dimension 1: Environmental Degradation
This dimension isolates acoustic conditions while keeping linguistic content fixed:
- Reverberation (RT60: 0.4 / 0.8 / 1.6s)
- Far-field recording (4–16m)
- Telephony codecs (GSM, G.711)
- Noise gaps
- Signal clipping
Figure 1. Robustness of multilingual ASR under real distribution shifts in the WildASR benchmark
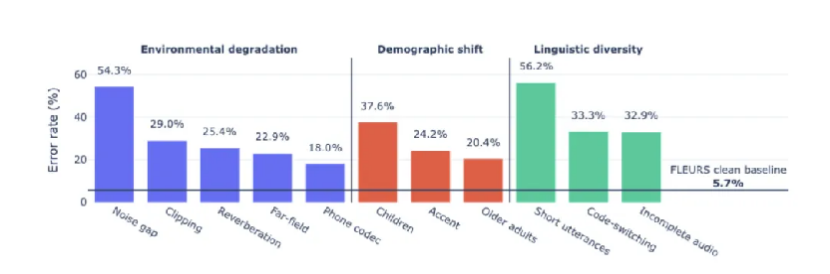
As shown in Fig. 1, all evaluated models exhibit sharp and uneven performance degradation under OOD conditions.
The gap between clean benchmark performance and real-world robustness is both significant and inconsistent across systems.
Table 2. Impact of environmental degradation on multilingual ASR performance
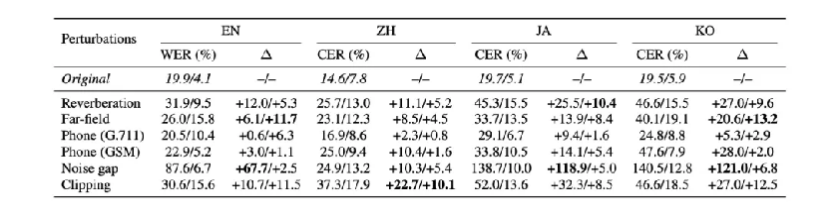
Noise gap conditions cause the most severe degradation for Japanese and Korean, with error rates exceeding 100%.
More importantly, conversational speech is affected far more than read speech.
In fact, the WildASR benchmark explicitly incorporates conversational datasets from MagicData, alongside read datasets such as FLEURS, precisely to capture real interaction patterns.
This comparison highlights a key limitation of current evaluation practice:
models trained and validated on read-style speech often fail when exposed to spontaneous, multi-speaker conversational data.
V. Dimension 2: Demographic Shift
This dimension evaluates performance across underrepresented speaker groups:
- Children (irregular rhythm, high pitch)
- Elderly speakers (low volume, breathy voice)
- Accented speech
Table 3. ASR performance under demographic shift
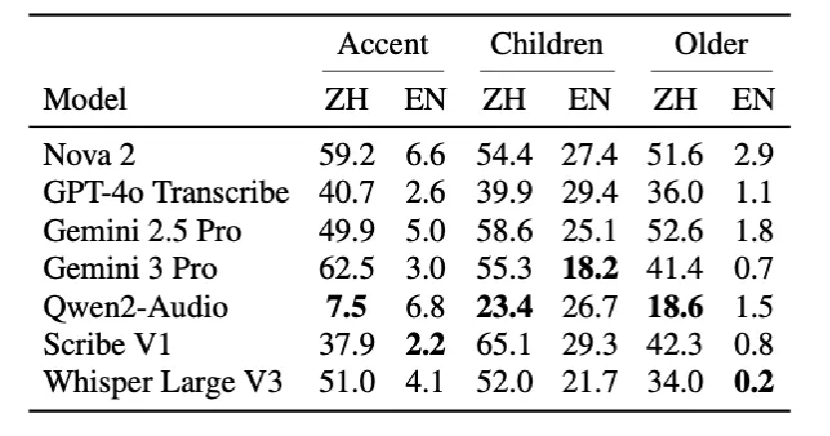
English generally shows stronger robustness, while Chinese exhibits significantly higher error rates across accents, children, and elderly speakers.
Even the best-performing models still reach 18.2% WER on English children’s speech, making this a critical bottleneck for deployment.
Figure 4. Performance variation of Gemini 2.5 Pro across demographic subsets under 10 prompt variations
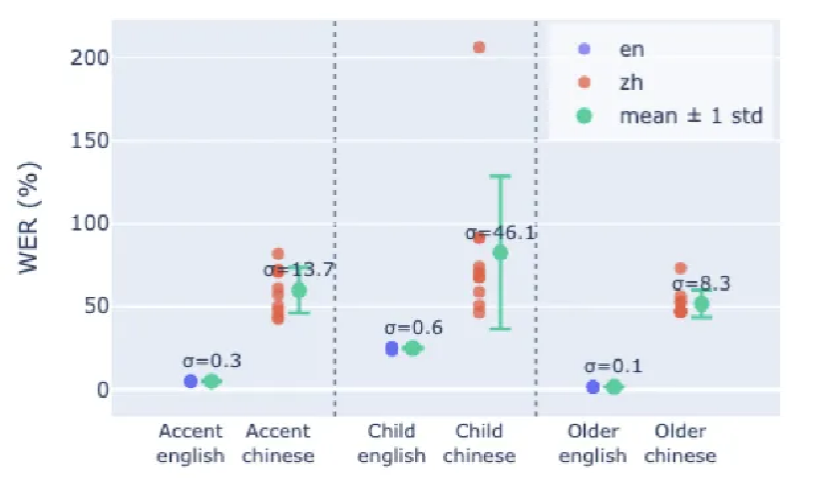
The results reveal substantial performance variability across prompt formulations.
Chinese subsets show extremely high sensitivity, with a standard deviation of up to 46.1%, while English remains relatively stable.
In practice, this means that even small changes in prompt phrasing can lead to significant performance differences in multilingual settings.
VI. Dimension 3: Linguistic Diversity
This dimension focuses on linguistic phenomena that are common in real conversations but underrepresented in training data:
- Short utterances (≤6 tokens)
- Truncated speech
- Code-switching
Table 4. ASR performance and hallucination behavior under linguistic diversity conditions
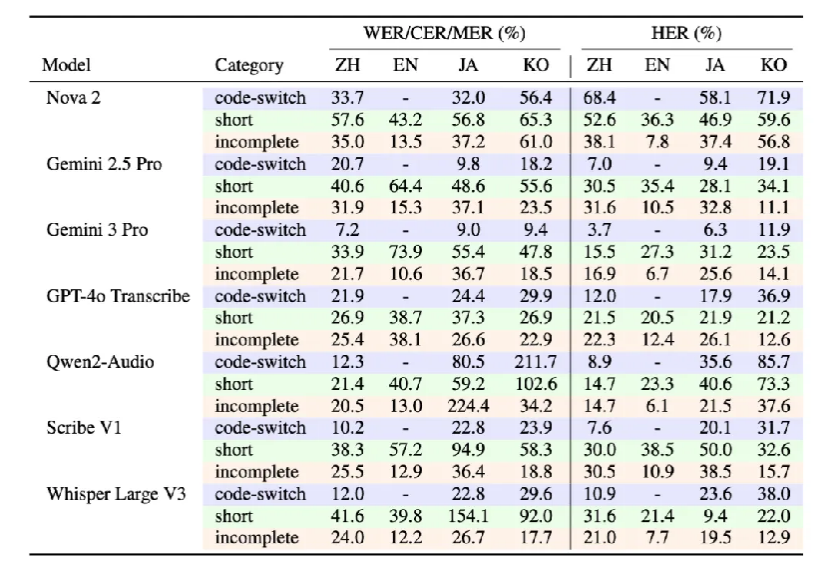
Short utterances exhibit error rates between 38.7% and 73.9%, with some models exceeding 100%, indicating extensive hallucinated insertions.
HER (Hallucination Error Rate) significantly exceeds WER, highlighting the risk of semantic distortion rather than simple transcription errors.
Representative Failure Cases
- “Yeah” → “I don’t know if I can.”
- truncated “who identified” → completed into a full sentence
- clipped “ah yeah” → unrelated semantic output
These behaviors indicate that modern ASR systems increasingly act as generative models, rather than purely deterministic recognizers.
VII. Key Findings
1. Multilingual ASR remains unresolved
Figure 2. Error heatmap of seven ASR models evaluated on the WildASR benchmark
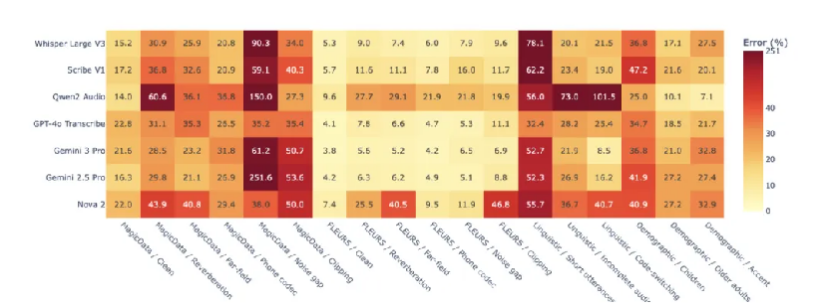
No model demonstrates consistent robustness. Each exhibits localized strengths alongside severe failure regions.
2. Robustness does not transfer
The same perturbation affects languages differently.
For example, noise gaps have limited impact on English and Chinese but are highly destructive for Japanese and Korean.
3. Real speech is essential
Synthetic children’s speech yields only 3.7% error, whereas real data increases to 21.7%, significantly underestimating real-world risk.
4. Hallucination is a critical safety risk
Under noise, truncation, and short utterances, models frequently generate plausible but incorrect content, posing risks for downstream systems.
VIII. Beyond WER: Practical Diagnostic Tools
1. P90 Inflection Analysis
Figure 3. Error dynamics of Qwen2-Audio under increasing reverberation
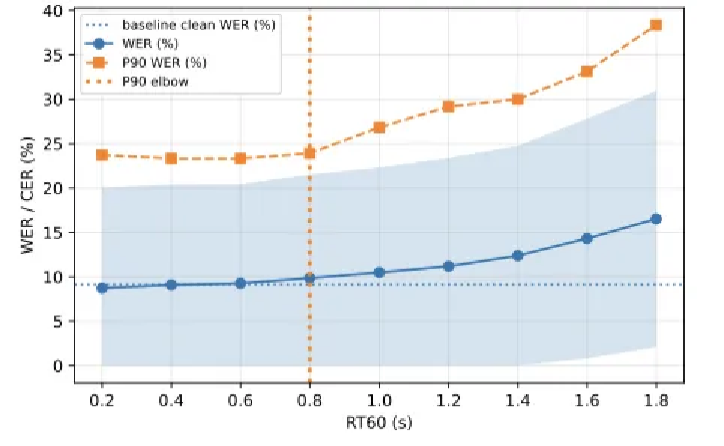
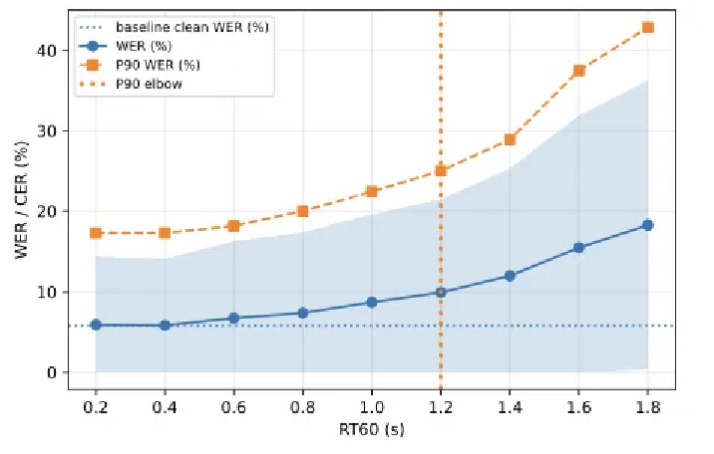
As distortion increases, average WER rises gradually, while the 90th percentile error increases sharply.
The inflection point defines the deployment instability threshold, capturing tail-risk behavior.
2. Prompt Sensitivity Profiling
By evaluating multiple semantically equivalent prompts, this method measures performance variance and reveals instability in instruction handling.
3. Hallucination Error Rate (HER)
HER captures semantic-level errors, distinguishing minor transcription mistakes from critical hallucinations.
Conclusion
WildASR reframes ASR evaluation as a multi-dimensional diagnostic problem.
It highlights a fundamental gap between benchmark performance and real-world reliability—particularly in voice agent systems, where ASR outputs directly influence downstream actions.
More importantly, these findings reinforce a broader shift in ASR development:
High-quality conversational and multi-speaker datasets are no longer optional—they are foundational.
The key question is no longer:
How accurate is the model?
but rather:
When it fails, how does it fail—and can those failures be trusted?