
Today, as AI can write poetry, create artwork, and generate code, we are still facing a warm and deeply human challenge: AI often struggles to understand regional voices.
For many users, especially older generations, standard Mandarin is not always the most comfortable way to express emotions. Authentic Cantonese, vivid Sichuanese, Wu Chinese, and other regional varieties are not only tools for communication, but also roots of culture and identity.
To support the real-world development of multi-accent and multi-dialect text-to-speech technology, Magic Data is pleased to officially announce the open-source release of five dialect TTS datasets: MagicData-Dialect-TTS-Lite.
The boldness of Northeast China, the depth of the Central Plains, the spice of Sichuan, the warmth and softness of Jiangsu, and the vitality of Guangdong — five dialects, five voices, all brought together by Magic Data.

概览
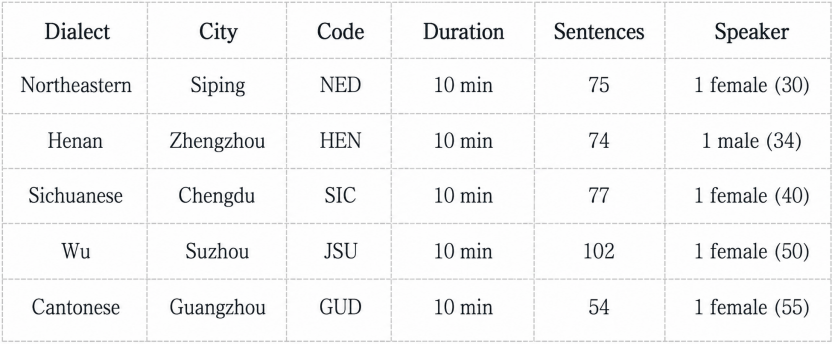
Total: 50 minutes / 5 native speakers
The Secret Behind Authenticity: Why Speakers Aged 30–60?
Many existing dialect datasets face an awkward problem: although the speakers can speak the dialect, their accents have already become “Mandarinized.”
Today, many young people can understand local dialects, but when they speak, the original “flavor” is often weakened.
To preserve the atmosphere and authenticity of pronunciation as much as possible, Magic Data applied a specific speaker selection criterion: we selected native speakers aged 30 to 60.
Why this age range?
Stable language habits: Native speakers in this age group have already formed stable language habits and are less likely to be affected by the reverse influence of standard Mandarin promotion.
Authentic expression: They retain more original vocabulary, intonation, rhythm, and pronunciation patterns.
Natural local atmosphere: Voices from this age group are better able to convey the unique sense of daily life, local character, and cultural texture of each region.
These speech samples are no longer “textbook-style” dialect speech. They are real dialects that live in everyday local life.
Dataset Features
1. Real native speakers with authentic accents
Each speaker was born and raised locally until adulthood. The local dialect is used in their family and main social environment.
2. Daily-life content coverage
The content covers daily scenarios such as weather, food, family conversations, numbers, time and dates, and a small amount of emotional expression.
The dataset does not include complex professional terminology, news reading, or poetry recitation, in order to avoid style deviation.
3. Clean and quiet recording environment
All recordings were collected in a clean and quiet indoor environment.
Audio format:
- 48kHz
- 16-bit
- Mono WAV
4. Moderate sentence length, suitable for TTS modeling
Each sentence is approximately 5–20 seconds long, with an average duration of around 10 seconds.
Sentences are naturally segmented according to punctuation, without forced cuts.
Annotation Guidelines
Chinese character transcription: Standard Chinese characters are used for transcription, while dialect-specific words are restored and preserved where applicable, such as the Northeastern expression “咋整” and the Sichuanese expression “耍朋友.”
Number annotation: Numbers are written in text form.
Important note: Dialect sentences are not forcibly “translated” into standard Mandarin. The original dialect wording is preserved.
Example:
Original Northeastern Chinese sentence:这事儿咋整啊?
Transcription:这事儿咋整啊?
Open-Source Data Structure
dialect-tts-lite/
├── Northeast
│ ├── ProsodyLabeling
│ │ └── txt
│ └── wav
│ └── wav/ # 75 audio files
├── Henan
│ ├── ProsodyLabeling
│ │ └── txt
│ └── wav
│ └── wav/ # 74 audio files
├── Sichuan
│ ├── ProsodyLabeling
│ │ └── txt
│ └── wav
│ └── wav/ # 77 audio files
├── Jiangsu
│ ├── ProsodyLabeling
│ │ └── txt
│ └── wav
│ └── wav/ # 102 audio files
└── Guangdong
├── ProsodyLabeling
│ └── txt
└── wav
└── wav/ # 54 audio files
Recommended Use Cases
Suitable for:
- Zero-shot / few-shot baseline testing for multi-dialect TTS models
- Acoustic analysis of dialect phonetic features
- Comparative experiments in academic papers
Not suitable for:
- Directly training production-level dialect TTS products, as this is a non-commercial lite release with limited data volume
- Evaluation of extreme scenarios, such as noisy environments, far-field speech, or children’s voices
If these 10-minute dialect subsets spark your interest, contact us to learn more about the full commercial version.
授权方式
Open-source license: CC BY-NC-ND 4.0, for non-commercial use only.
The dataset is suitable for academic research, personal development, and model evaluation.
Download and Contact
Dataset link:
https://magichub.com/datasets/magicdata-dialect-tts-lite
P.S. Select the dialect region you are interested in to download the corresponding dataset.
For inquiries about the full commercial version, please contact: business@magicdatatech.com