
With the rapid progress of artificial intelligence, text-to-speech (TTS) systems can already generate intelligible speech. However, enabling AI to speak more naturally—to sound like a real person engaged in conversation—remains a key research challenge. Most traditional TTS systems rely on “half-duplex” corpora with strict turn-taking, which struggle to reproduce behaviors ubiquitous in real conversations: overlapping speech, real-time backchannels, interruptions, and affective alignment.
To address this, the Magic Data research team conducted a study focused on full-duplex conversational speech. The related paper, “Open-Source Full-Duplex Conversational Datasets for Natural and Interactive Speech Synthesis,” has been posted on arXiv.

Paper link: https://arxiv.org/abs/2509.04093
Background and Motivation
Studies show that over 40% of utterances in natural human dialogue contain overlap, including interruptions, real-time backchannels (e.g., “mm-hmm,” “yeah”), and non-verbal vocalizations (e.g., laughter). These dynamic interactional features are pivotal to whether synthetic speech feels “human.” Yet many widely used speech corpora (e.g., Switchboard, DailyTalk) still assume strict turn-taking and lack explicit annotation and alignment for overlapping speech, limiting the training of full-duplex interactive speech models.
To overcome this limitation, the Magic Data team constructed bilingual (Chinese–English) full-duplex conversational datasets to provide dialog-oriented TTS systems with high-quality training data that better match real interactive settings.
Data Construction and Methodology
Core Innovation
The team released two open-source full-duplex conversational datasets (Chinese: 10小时; English: 5小时). Using dual-track (dual-channel) recording, the datasets capture authentic conversational dynamics—including overlaps, backchannels, and laughter—that are essential for natural, interactive TTS.
Data Collection Setup
We recruited native 中文 and 英语 speakers. All conversations were recorded in an acoustically isolated room, with each speaker recorded on a separate device, producing high-quality channel-separated audio tracks. Speakers were paired in twos, with a preference for familiar pairs (e.g., friends, family) to elicit more natural interactional behavior.
Conversation topics were unrestricted; speakers freely chose everyday subjects of interest. This yields broad contextual coverage and a rich variety of speech phenomena.
Transcription and Annotation
All qualified recordings were manually transcribed and annotated by trained annotators, including:
- Speaker identity and gender
- Precise timestamps (start and end)
- Overlapping speech interval labels
- Paralinguistic events (e.g., laughter, interjections) and dialogue-act tags
We placed special emphasis on voice activity detection (VAD) segmentation based on semantic completeness, ensuring each segment is not only acoustically intact but also semantically self-contained, making it suitable for TTS training and for tasks involving semantic understanding.
Data Statistics and Structure
The collection comprises 35 conversations—27 Chinese sessions (10小时) and 8 English sessions (5小时)—produced by 14 distinct speakers. All audio is released as 16 kHz, 16-bit PCM, accompanied by time-ordered two-party transcripts in which each line contains timing information, a speaker ID, and the text.

Table 1. Dataset statistics
File naming follows a structured rule to facilitate organization and retrieval: A<SessionID>_S<TopicID>_0_G<SpeakerID>.
Experimental Validation and Results
To verify the datasets’ effectiveness, we used CosyVoice-300M as a baseline model. We generated speech before and after fine-tuning on the full-duplex data and evaluated performance using both objective acoustic metrics and subjective listening tests.
Objective Evaluation
After fine-tuning, the model improved on all metrics. In particular, F0 (fundamental frequency) distance decreased significantly—7.08% (Chinese) and 3.67% (English)—indicating prosody and rhythm that are closer to natural speech.
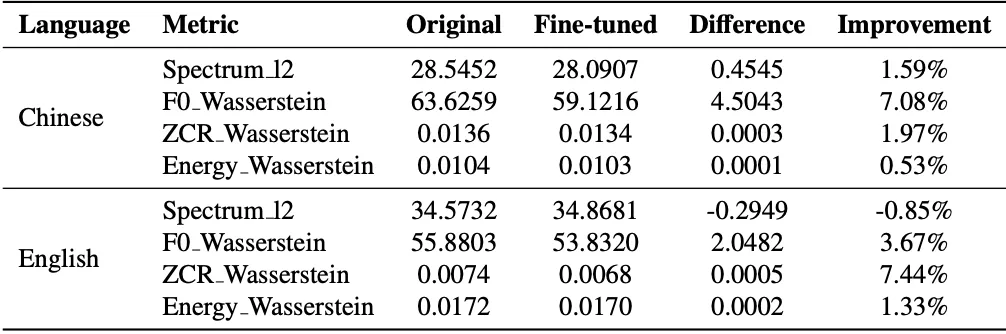
Table 2. Post-fine-tuning improvements on objective metrics (Chinese and English subsets)
Subjective Evaluation
We recruited native 中文 and 英语 listeners for A/B preference tests. Results show:
- Chinese TTS: 45.0% of listeners preferred the fine-tuned model as more natural.
- English TTS: 46.4% of listeners preferred the fine-tuned model as more natural.
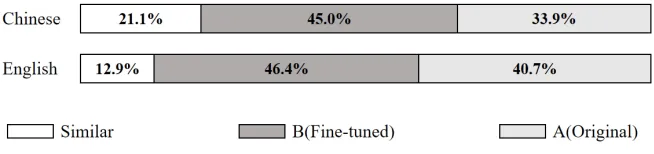
Figure 1. A/B preference distribution
MOS (Mean Opinion Score) ratings increased consistently on both naturalness and intelligibility dimensions.

Table 3. Chinese and English MOS comparison
Conclusion: Fine-tuning with full-duplex conversational data significantly enhances interactive realism and overall naturalness of the synthesized speech.
Data Availability and Licensing
The datasets are publicly available via ScienceDB under the CC BY 4.0 license, permitting academic use with attribution.
They are also released on the MagicHub open-source community:
- Chinese Full-Duplex Dataset:
https://magichub.com/datasets/multi-stream-spontaneous-conversation-training-datasets_chinese/ - English Full-Duplex Dataset:
https://magichub.com/datasets/multi-stream-spontaneous-conversation-training-datasets_english/
Beyond the open-source releases, Magic Data can provide larger-scale, multilingual, commercially licensable full-duplex conversational datasets to meet enterprise application needs.
Conclusion and Outlook
By constructing high-quality Chinese–English full-duplex conversational datasets and validating their impact on TTS naturalness and interactive authenticity, this work provides an important data foundation and experimental evidence for advancing conversational speech synthesis. We look forward to future research that brings forth even more natural and intelligent dialogue systems.
Paper title: Open-Source Full-Duplex Conversational Datasets for Natural and Interactive Speech Synthesis
Paper link: https://arxiv.org/abs/2509.04093
For further details or collaboration inquiries, please contact: business@magicdatatech.com