
Voice cloning is shaping the future
Since the start of 2023, there has been a growing buzz around voice cloning, or voice reproduction, within the realm of speech synthesis. This surge in interest is evident in the increasing number of research papers dedicated to the topic and the growing investment from both large corporations and startups venturing into this domain. This trend underscores the immense potential of voice cloning technology. Amidst the wave of research into large speech synthesis models, voice cloning has emerged as a sub-task that has made substantial advancements, particularly in handling extensive speaker datasets. Coupled with its promising applications, its effectiveness has become a pivotal metric in the exploration of these expansive speech synthesis models. In the industrial sector, from ElevenLabs' high-quality voice cloning service to OpenAI's recent release of ChatGPT's voice interaction feature that supports voice cloning, there has been a wide range of promising developments for the field of voice cloning technology.
With the increasing accessibility of voice cloning technology, we are poised to witness a transformative shift in the way we interact with technology and information through the rising utilization of voice assistants and virtual aids. Concurrently, voice reproduction technology is set to revolutionize the realms of movies, TV shows, music production, and entertainment, including gaming. This technology empowers artists and creators to fashion distinctive voices for fictional characters and offers users a more immersive experience within virtual worlds. Moreover, voice reproduction technology holds the potential to facilitate communication for individuals with hearing impairments or speech difficulties, promoting greater inclusivity and fairness within society.

Introduction to voice cloning technology
Voice cloning is a subset of speech synthesis, a technology also known as text-to-speech conversion. In traditional speech synthesis, the process involves analyzing the input text, breaking it down into smaller semantic units, using a neural network acoustic model to transform these units into acoustic features, and finally employing a vocoder, also based on a neural network, to produce the corresponding audio output. In essence, users simply input the text they want to be spoken, and the system generates audio with a predefined speaker or a selection from multiple speakers.
However, speech cloning differs significantly from standard speech synthesis. In addition to inputting the desired text, users are required to provide a sample audio (referred to as a "Prompt") of the speaker they wish to replicate. This audio can either be the user's own voice or from any speaker, with no restrictions on content or duration, typically staying within 10 seconds. The resultant audio output will then mimic the provided speaker's voice while articulating the user's input text. Ideally, the cloned voice should closely resemble the provided speaker. One of the key challenges lies in the model's ability to filter out background noise, recording conditions, and equipment interference from the input audio while retaining the unique characteristics of the target speaker. Furthermore, the model must consider whether to replicate the speaker's accent, speech patterns, and other prosodic features, depending on the application context.
The core components of speech synthesis encompass text analysis, the acoustic model, and the vocoder. In speech cloning, text analysis typically remains unchanged, while the vocoder may require training on multi-speaker data to achieve a universal vocoder or may be jointly optimized with the acoustic model. However, the most significant divergence lies in the acoustic model, and much of the industry research in this domain focuses on this particular aspect.
Currently, voice cloning technology offers various solutions both in academia and industry. However, most of these solutions leverage Neural Audio Codec technology to encode audio into discrete tokens. For instance, VALL-E(available at https://browse.arxiv.org/pdf/2301.02111.pdf), inspired by LLM (Large Language Models), utilizes the language model's classification output to predict discrete acoustic tokens, which are then decoded by the codec to produce audio. This approach allows for a prediction mode similar to a language model, enabling the continued generation of acoustic tokens based on the input prompt, thereby achieving the effect of voice cloning.
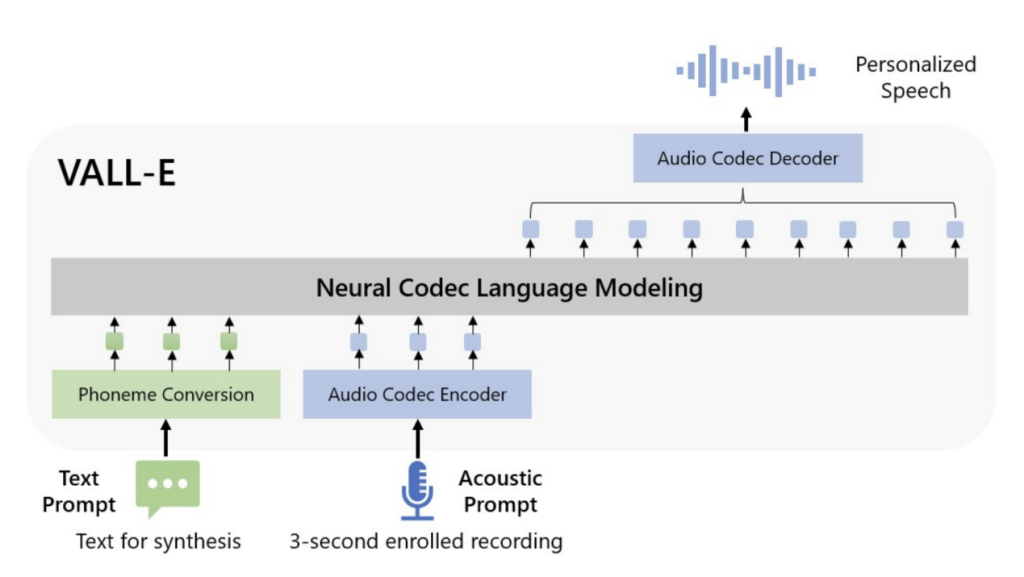
Google's SPEAR-TTS (accessible at https://browse.arxiv.org/pdf/2302.03540.pdf) employs discrete tokens and token continuations, employing two sequential-to-sequential (seq2seq) models to handle the "reading" and "speaking" stages. This approach makes use of substantial non-parallel data to attain a high degree of speech cloning similarity. A visual representation of this process can be found in the following schematic diagram:
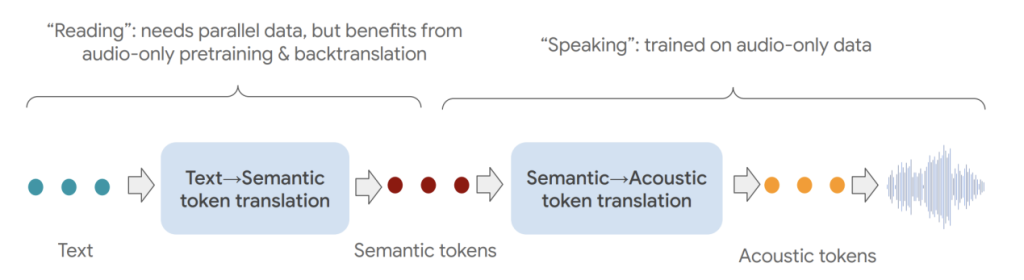
In the case of NaturalSpeech2 (available at https://browse.arxiv.org/pdf/2304.09116.pdf), there's a dual approach being taken. Firstly, it leverages continuous tokens to simplify the complexities of the acoustic model, while simultaneously incorporating a diffusion model to enhance its contextual learning capabilities. Secondly, it employs Attention as the condition module to introduce prompts into the acoustic model. The schematic diagram illustrating these techniques is provided below:
Mega-TTS adopts discrete tokens to capture prosodic details, and it retains the use of the Mel spectrum in its acoustic component.
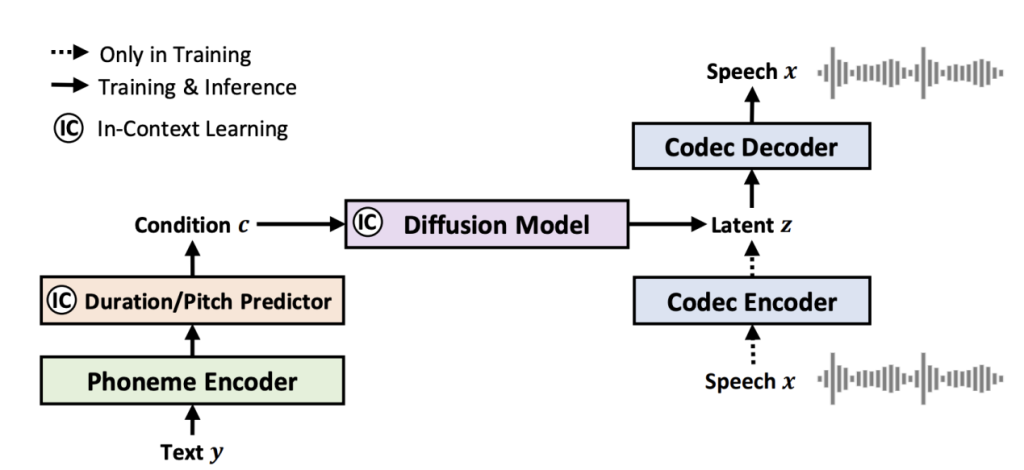
Furthermore, there exist notable speech cloning solutions within both the open-source community and the industry. A prime example is Tortoise-TTS, which also employs an autoregressive approach for predicting discrete acoustic tokens (available at https://browse.arxiv.org/pdf/2305.07243.pdf). However, what sets it apart is its utilization of a diffusion model to forecast the Mel spectrum from these tokens. Many companies, including ElevenLabs and OpenAI, often draw inspiration from similar frameworks. You can visualize this approach in the schematic diagram provided below:
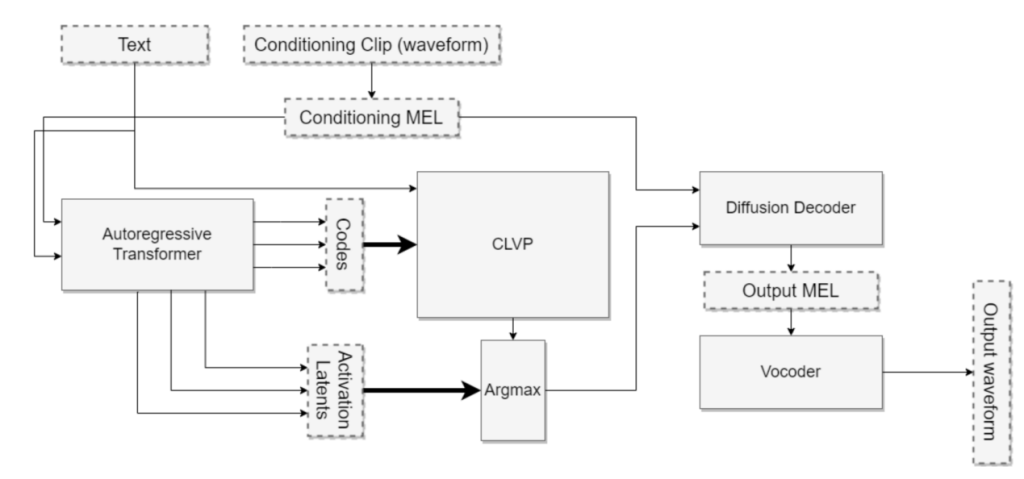
It's worth mentioning that Tortoise-TTS takes the latent hidden layer vector of the transformer as input for the diffusion model to predict the Mel spectrum. This approach highlights the extent to which codec tokens with excessive compression ratios can lead to substantial information loss. In such cases, having richer textual information becomes crucial to restore pronunciation, rhythm, and even sound quality. As for Bark-TTS, it shares similarities with Spear-TTS and is rooted in AudioLM, so I won't delve into its specifics here.
In summary, the landscape of speech cloning technology is currently marked by a multitude of approaches. Decisions regarding whether to opt for autoregressive or non-autoregressive methods, employ speech continuation, or adopt different condition schemes, and whether to stick with the traditional Mel spectrum-based vocoder or engage in joint optimization with acoustic models, all hinge on factors like a company's data resources, service standards, and product application scenarios. Nonetheless, the ultimate measure of success still rests on the quality of the end product. Perhaps, with the eventual release of OpenAI's voice cloning service, the technology will begin to consolidate into one of its dominant branches.
The industrial impact of voice cloning
For providers of speech synthesis services, voice cloning presents a substantial opportunity to slash the costs associated with creating new voices. In the realm of traditional speech synthesis, creating new voices typically demands copious amounts of high-quality speech data from the target speaker. This involves an intricate process, spanning from studio recording, data processing, model training, testing, to deployment, which incurs significant time cycles and capital expenditures. However, voice cloning flips the script, requiring only minimal recording and testing expenses. The reduction in testing costs stems from the stability exhibited by large-scale speech replication models when handling high-quality speech prompts, provided that model parameters remain unchanged. This method proves to have fewer instances of undesirable outcomes when compared to the traditional approach of fine-tuning the parameters of the entire acoustic model. Moreover, voice cloning enables rapid expansion of voice diversity on a large scale, with virtually no additional outlay for model training and deployment. These newly cloned voices seamlessly integrate with existing ones, remaining indistinguishable to users.
For businesses, voice cloning unlocks fresh possibilities across various domains, including personalized human-computer interactions, digital avatars, and language education. It can be expected that numerous untapped opportunities await exploration in diverse fields.
However, the availability of voice cloning services accessible to the general public remains somewhat limited. Prominent providers in this space include ElevenLabs, Speechify, Play.ht, among others, though the focus has predominantly been on English cloning. OpenAI recently unveiled its speech synthesis technology, seamlessly integrating it into ChatGPT's voice interaction capabilities. Although direct voice cloning services are not yet offered, OpenAI has hinted at the potential for voice cloning within its speech synthesis technology. To the best of my knowledge, there are currently no mainstream Chinese voice cloning services offered by domestic companies. The primary obstacle hampering public proliferation continues to be the intricate web of regulatory and legal complexities. Much like the paradigm shift ushered in by GPT, these challenges are poised to drive the advancement of research areas such as generated speech detection, audio replay attacks, and speech watermarking.
Data
In the era of large models, the importance of data has become increasingly evident. When it comes to speech cloning or large-scale speech synthesis models, the focus has shifted from seeking "high quality and stable speaking styles" to embracing "a multitude of speakers with varying speaking styles." Traditional speech synthesis relies on a "pre-training + fine-tuning" process, with the emphasis squarely on "fine-tuning." This typically necessitates substantial studio-level speech data from a target speaker, ensuring a specific, stable speaking style–often a standard reading style unless otherwise specified. However, for speech cloning to achieve a highly authentic cloning effect, a minimum of 10,000 speakers is required. Therefore, the number of speakers in the dataset directly impacts the synthesis similarity. Interestingly, a large number of speakers does not necessarily translate to a massive volume of data. The data for each speaker can range from half an hour to as short as one minute. For relatively compact models, the number of diverse speakers proves far more critical than the total data volume. Furthermore, considering the synthesis results of ChatGPT, expanding the application scenarios of speech synthesis for a more "natural" and "human-like" output necessitates moving beyond the confines of standard reading styles. It should embrace a closer approximation to natural speaking styles, even incorporating pauses for thought, making it increasingly challenging to distinguish between genuine and synthesized voices. Thus, in contrast to traditional Text-to-Speech (TTS) data, it is advisable to include relaxed, conversational-style voice data in speech reproduction datasets. This enables the model to better align with the prompts of real users.
However, it's important to note that despite the lower standarded data requirements for sound replication in comparison to traditional speech synthesis, certain standards still must be met. For instance, an ideal sampling rate for speech data is 48 kHz. These requirements act as a threshold for entry into this domain. Collectively, it's worth mentioning that there aren't a plethora of voice datasets in the market that fully meet the aforementioned standards.
To expedite and enhance the development of voice cloning technology for a wider array of companies, Qingshu Smart has proactively introduced the "48kHz Multi-Speaker Speech Dataset for Voice Cloning." Inclueded accented English and Chinese, this dataset boasts an impressive 48 kHz high sampling rate and has been meticulously gathered by tens of thousands of individuals. It encompasses diverse, natural content and spans over 10,000 hours in duration, rendering it an exceptional resource for training speech replication models. Several leading AI companies have already harnessed this dataset to develop voice cloning applications, with its data quality rigorously tested and empirically acknowledged.

For a sample of the data, you can listen here: Link to Data Samples-English&Link to Data Samples-Chinese. For further details regarding the dataset, please don't hesitate to reach out to business@magicdatatech.com.