

When we are immersed in TikTok, Kuaishou, the world is quietly refreshing our cognition. Previously, through AI tools such as DALL-E, MidJourney and CrAIyon, ordinary users could enter simple text content and create artistic illustrations through artificial intelligence.
Recently, Meta and Google have gone a step further on this basis, successively launching the black technology of generating video from text and voice. Not only can you generate pictures, but you can also generate emotional video content. Generate a matching short video based on the text information entered by the user depicting a scene. These videos are very interesting, Meta also gave a sample website: https://make-a-video.github.io/
In addition to Meta, Google is also offering two video generation competitors at the end of the holidays - Imagen Video and Phenaki. According to Google CEO Sundar Pichai, Imagen Video has a higher resolution than Meta's Make-A-Video, and can generate 1280*768 video segments at 24 frames per second. Sample website: https://imagen.research.google/video/

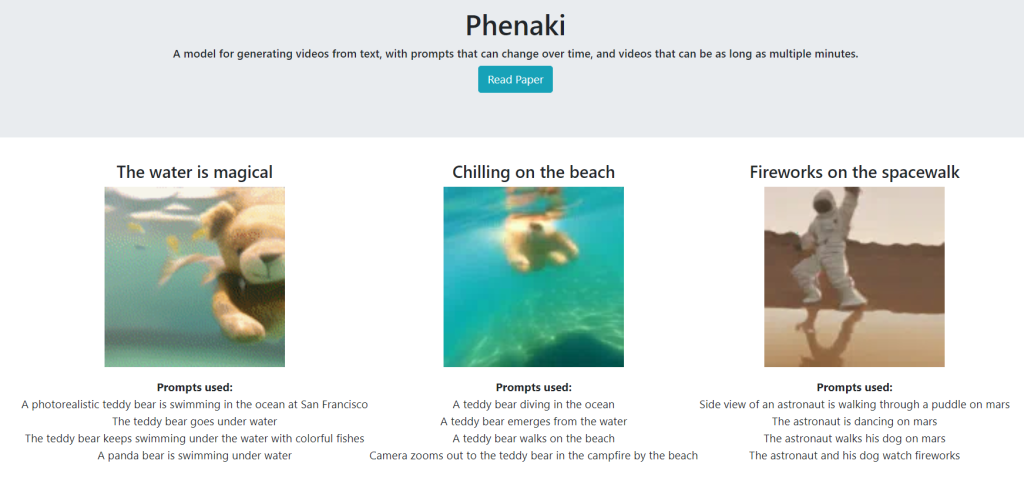
In addition, Phenaki can generate a video of more than 2 minutes based on a text description of about 200 words, telling a complete short story, comparable to a small director. Sample website: https://phenaki.video/
What technology is behind the various text-generating video technologies mentioned above?
The model architecture of Make-A-Video is shown below. The technology is improved on the basis of the original Text-to-Image. The main motivation is to understand what the world looks like, and to describe the text image data paired with it, and from unsupervised In-Video Learn real-world camera movement when recording video.
First, the authors decouple the full temporal U-Net and attention tensors and approximate them both spatially and temporally. Second, the authors design a spatiotemporal pipeline to generate high-resolution and frame-rate videos, which contains a video decoder, interpolation model, and two super-resolution models, enabling various text generation applications including Text-to-Video.
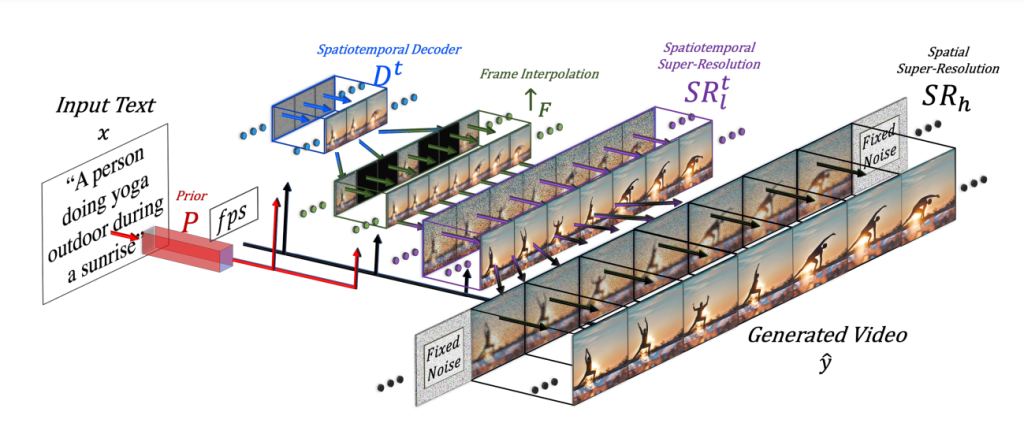
The high-level architecture diagram of Make-A-Video shows that, given an input text x translated into an image embedding by a prior P, and a desired frame rate fps, the decoder Dt generates 16 frames of 64 × 64 resolution, then It is interpolated to a higher frame rate by ↑F, and the resolution is increased to 256 × 256 for SRt l and 768 × 768 for SRh, finally generating a video with high spatiotemporal resolution y^.
Imagen Video is a diffusion model based on the recent fire, directly inheriting the image generation SOTA model Imagen.
In addition to the high resolution, three special abilities are displayed.
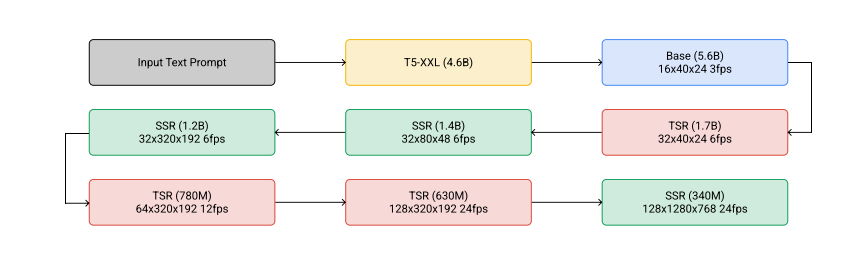
First of all, it can understand and generate works of different artistic styles, and the 3D structure of the object will not be deformed in the rotating display. Imagen Video is a collection of a series of models. The language model part is Google's own T5-XXL, and the text encoder part is frozen after training. Among them, the language model is only responsible for encoding text features, and the work of text-to-image conversion is handed over to the later video diffusion model. Based on the generated image, the basic model continuously predicts the next frame in an autoregressive manner, first generating a 48*24 video with 3 frames per second. The flow chart from text prompt input to video generation is shown in the following figure:
Before Phenaki, AI models could generate an ultra-short video with a specific cue, but were unable to generate a 2-minute coherent video. Phenaki implements a brain storyline, generating 2+ minutes of video.
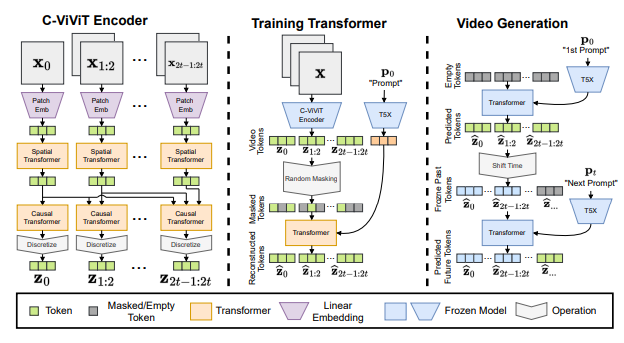
The researchers introduced a new causal model to learn to represent videos: treating a video as a temporal sequence of images. The model is based on Transformer, which can decompose video into discrete small representations, and decompose video in temporal causal order. That is, a single cue is encoded by a spatial Transformer, and then multiple encoded cues are concatenated using a causal Transformer. Its flow chart is as follows:
The impact of text-generated video
With the rapid development of text-generated video technology, in the future, the videos of major short video platforms may no longer be live-action shows, but synthetic video shows.
AI is revolutionizing industries, bringing challenges as well as more progress. AI will eventually lead to more jobs, says Daniel Jeffries, Stability AI's new chief information officer. Challenges and opportunities coexist at any time, and grasping the pulse of the times can create a better future.