
作者:谢磊
编辑:麦吉哈
在Data & AI Con Shanghai 2023的“数据工程与大模型落地实践”分会场中,西北工业大学教授/博导、音频语音与语言处理实验室负责人谢磊老师为我们带来了一场精彩的分享,主题聚焦于「语音生成式模型前沿进展」。
当前,以GPT为代表的生成式模型成为人工智能领域的最大热点。语音人机交互尤其以ChatGPT为代表的“超级助手”入口,作用至关重要。本报告将探讨语音作为生成式模型的前沿进展,包括典型方案与技术、挑战问题、效果展示和未来展望。

超拟人TTS
超拟人TTS

所谓超拟人 TTS ,其实是我们为了对标像 ChatGPT 这种非常拟人化的合成的声音。要实现这样的声音合成,我们至少要考虑两方面:
第一我们自然的对话里有非常多的口语化事件,包括延长音、停顿、口语化词的填充,还有重复、倒装、重读等等,这些都让我们的说话非常自然,同时还有一些笑声,甚至清嗓这种声音,都是能够感觉到对话更加真实的。
第二我们在建模的时候,除了这些口语化事件的复现之外,还要考虑上下文,我们要考虑文本和声学的上下文,让我们的语境适配情绪,情感也能够适配等等。
超拟人TTS:口语事件/语气词/情绪/情感
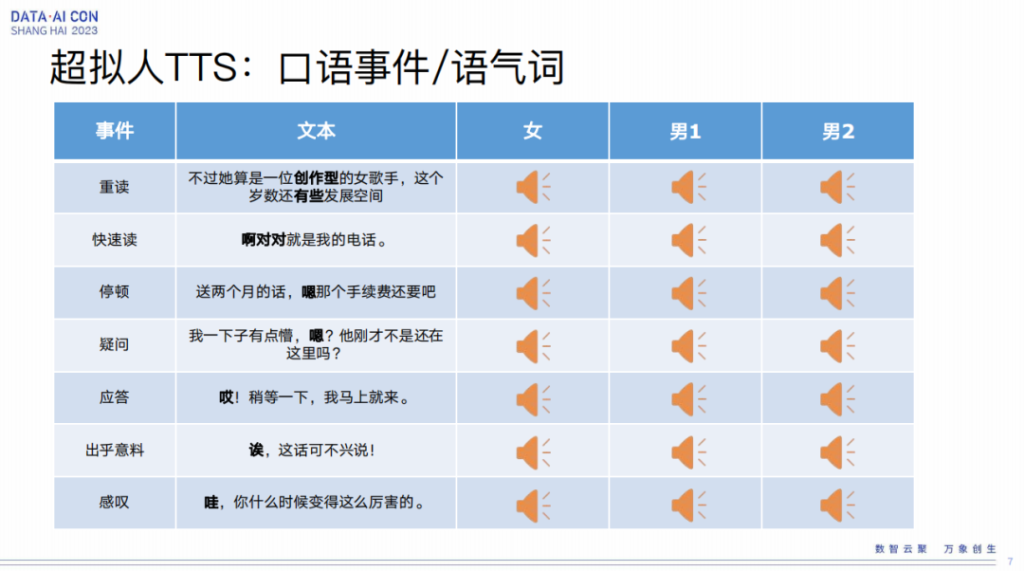
在这方面我们做了非常多的基础性工作,我们可以实现各种各样的口语化事件的合成,比如快语速、疑问、感叹、口水音、表现力非常强的词语的合成,还有各种各样情绪的复现,比如撒娇等等。

我们把这些相关的口语化事件和情绪表达结合在一起,就可以做成两个 AI 的对话。我们可以把一对小夫妻在双十一的一个对话合成出来,效果是这样的:
两个 AI 的聊天是可以生成的,现在有了大模型的加持,我们可以让它的表现力做得更加自然,刚刚展示的还是我们上一代技术的效果。

我们也可以用低质的数据,比如找一个客服,把这个客服的声音进行处理,我们就可以拿这个客服的数据去构建一个 AI 客服。这块我们是跟美团在合作,大家可以打美团的客服电话体验一下正式上线的这种感觉,我们可以听到非常自然的客服的对话,这个已经上线在了美团的外呼和内呼机器人。
高表现力TTS
我们除了要做这种对话类的语音合成,在很多场景中我们也需要情感,还有长文本的生成,比如说有声书这类场景。
基于因素解耦的多风格多情感TTS
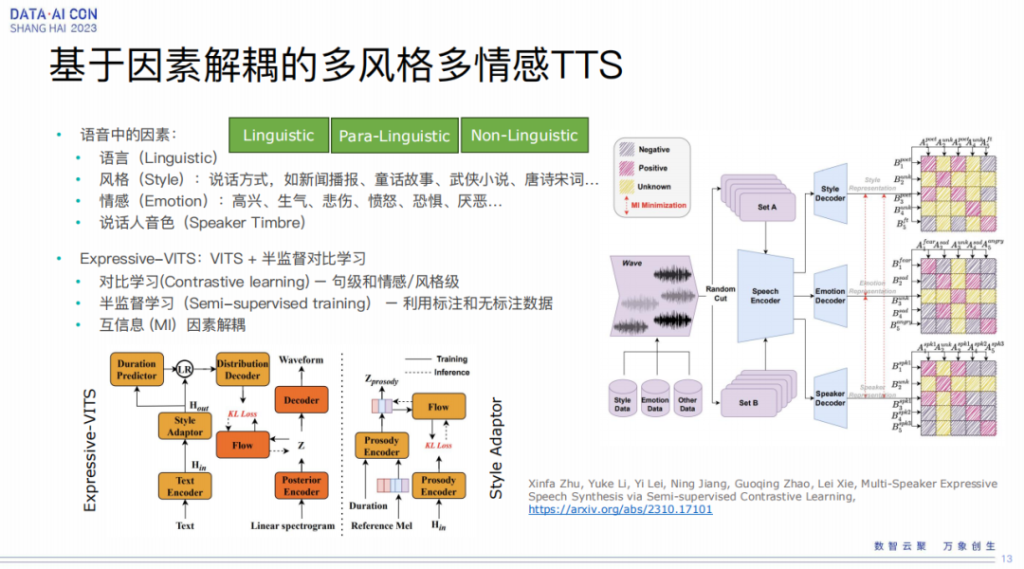
第一个要介绍的工作是基于因素解耦的多风格、多情感的语音合成。这个是指我们有很多音库,但每个音库只有一种风格、一种情绪,甚至没有情绪。
那我们能不能把这些数据都有效地利用起来?我们可以做到集内这些说话人有风格和情感的交叉,也就是这个说话人,比如录的是客服,我也可以让他读唐诗,可以让他讲故事,同时在讲故事过程中还可以有不同的情感,比如生气的表达、愤怒的表达等等,甚至我们还可以做到跨语种,比如郭德纲讲英语相声。
所以这个的目的就是把语音中的各种各样的因素进行有效的解耦,然后再进行重新的组合,就可以实现多风格、多情感的TTS。这块我们是基于VITS 这个模型,在这个基础上加入了对比学习,去学习句级和情感,以及风格级,自动的从无标注的数据里面去学习跟表现力相关的元素。
同时我们用半监督学习的方法,也就是我们有一些情感的标注,有一些风格的标注,结合这些无标注数据去做半监督的学习,有效利用这种无监督的数据。

我们的解耦用了互信息的解耦方式,所以我们就可以做到,比如中文说话音色的一个小朋友,让他高兴地去读诗歌,同时也可以让他用生气的口吻来讲,当然也可以有惊讶的这种风格。
从上图右侧的展示也可以看到我们的风格、情感的说话人是能够有效地进行解耦,它的这个分布也是比较开的。
我们可以再放一个例子,比如用我的声音去读童话故事,同时童话故事里边的每一句话也赋予不同的情感。
我们也可以让一个外国人讲中文,大家可以听一下,这是奥巴马的声音,我们可以用奥巴马的音色去读各种各样的风格的音频。
跨语种TTS中的零样本(Zero-shot)情感迁移
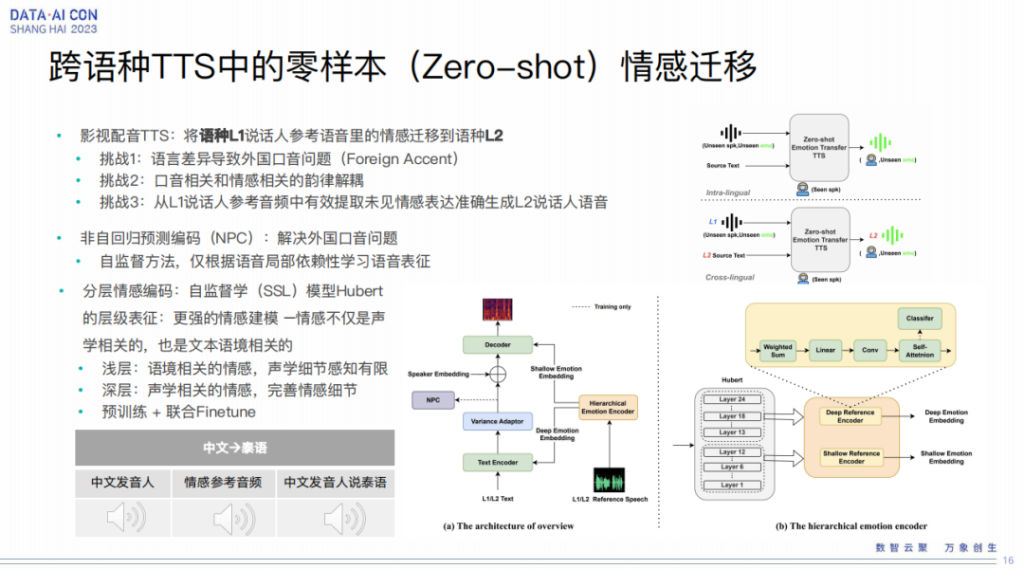
另外一种就是在影视配音里我们有这样一个需求,把某个语种的音色迁移到另外一个语种里,同时我们可以把原始语种里音频的情感也迁移到目标语种里。
要做这件事情,其实有三个挑战:
1、语言差异导致外国口音问题;
2、口音相关和情感相关的韵律解耦;
3、从L1说话人参考音频中有效提取未见情感表达准确生成L2说话人语音。
所以为了解决这个挑战,我们基于微软的 delightful TTS 框架的backbone加了一些东西,比如非自回归的预测编码,去解决外国口音的问题,这是一个自监督学习的方法。另外我们也利用 Hubert 模型去进行分层的情感编码, Hubert 里不同层的信息是各种各样的,成分的含量也是不一样的,比如我们可以认为浅层是跟语境相关,但是声学的细节感知有限,而深层的声学可以完善情感细节,所以我们可以有效利用多层的信息进行抽取。
这个我们是在跟爱奇艺合作,目的就是我们能把中文电视剧出海,比如到东南亚到泰国,可以翻译成泰语之后,用这种零资源的情感迁移的技术让泰语的配音里边也富有一些情感。我们可以放一小段片段,这是爱奇艺做的一个demo:
StyleS2ST:端到端语音到语音翻译中零样本风格迁移
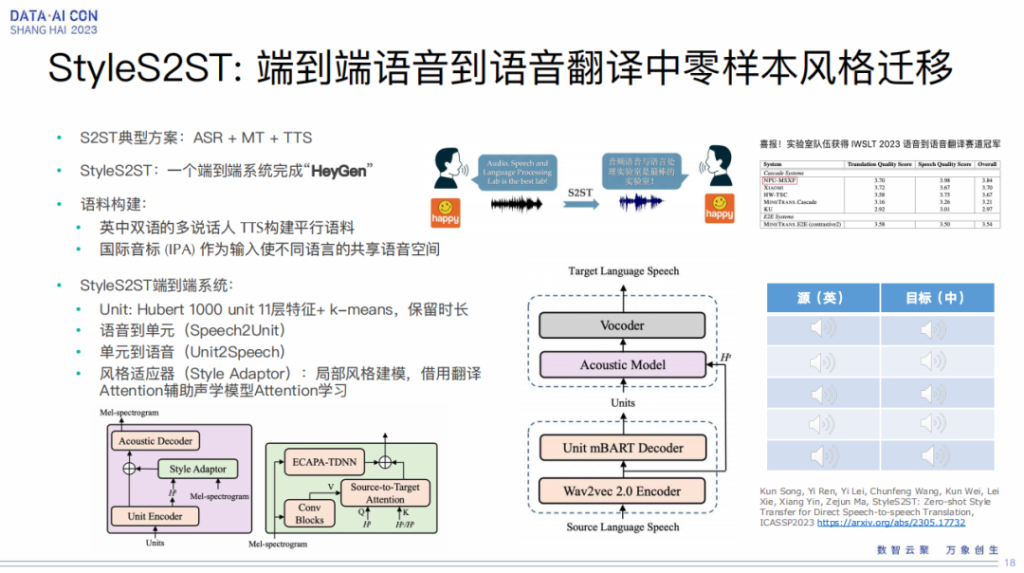
我们也做了语音到语音的翻译,目前也是翻译的一个热点,包括大家都知道的最近很火的hey Jean,可以让郭德纲带着他的腔调说英语,然后让霉霉说一口流利的中文。
那它是怎么实现的呢?典型的级联式的方案,就是先做语音识别,再做翻译,然后再做TTS,只不过TTS里边带有原始的说话人的音色。
我们正在想能不能做一个完全端到端,一个系统就可以打通所有的链条,一个系统完成从 source 到 target 语音到语音的翻译。我们这边做了一些有益的尝试,这也是跟字节跳动在合作的一个工作,这方面的语料是非常稀缺的,所以我们就先用一个多说话人多情感的TTS去生成了一堆平行的语料,然后我们用IPA作为语种之间共享的发音空间。
我们这个系统比较简单,其实就是一个两段式的系统,一个是Speech2Unit,一个是Unit 2Speech,Speech2Unit包括了Wav2vec 2.0 encoder和Unit mBART Decoder做翻译,然后到Units,Units 再通过声学模型声码器去合成出我们的目标语音。这里边 Units 我们也是用了Huber的特征做了kmeans聚类,同时我们也保留了时长的信息,我们知道时长是表现韵律非常重要的东西,所以我们用了这样一套技术,做到完全语音到语音的翻译,而且带有 source 的一些情感。
HiGNN-TTS:基于GNN与多层韵律建模的长语音合成
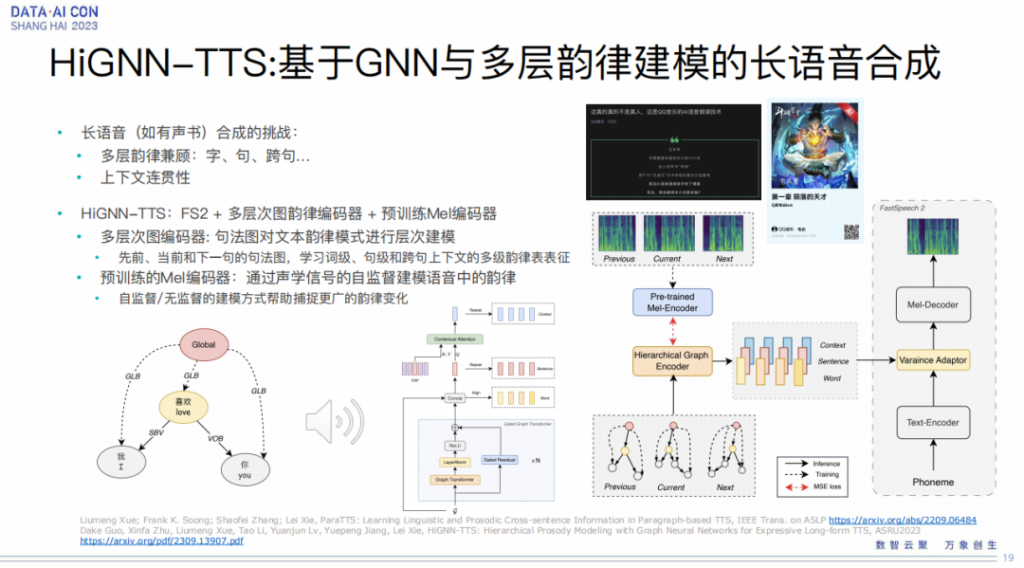
接下来给大家介绍的是长语音的语音合成,我们知道有声书这些其实也是我们语音合成想要解决的一个目标,但是要做好有声书的合成,我们要考虑非常关键的问题,就是多层韵律建模。因为我们人讲话的时候的韵律其实非常的微妙,有各种各样级别上的韵律的表达,包括字上的、词上的、句上的、跨句的、段落的,所以我们还要考虑上下文的连贯性。
在这方面我们也做了一些工作,我们用图神经网络去建模这个层级的韵律,然后我们用预训练的梅尔编码器进行韵律进一步的学习。所以多层这一块其实是指我们的句法树,实际上是考虑了上一句当前句和下一句,让它有一个更好的一个context,然后去建模上下文的一个韵律表征。
其实如果有了现在这个大模型,我们在大模型的一个基座模型上面拿有声书的数据做一个 fine tuning,可能也能做到非常好的表现力了。我们可以听一段有声书的例子:
基于自然语言描述的语音生成
所谓语音生成的目的,其实就是想生成一些新的音色、新的风格,然后我们就可以在下游任务里边有多样性,那最简单的方法就是我们做音色的差值,我们可以有 n 个人的声音,然后做一个blending,就可以做到音色之间的一个组合,当然我也可以做到多个人之间的一个混合。
但是今天我重点要讲的是我们能不能直接通过自然语言去生成我们想要的声音,这个其实是最自然的一种方式。在这一块,我们其实跟出门问问在合作,出门问问的魔音工坊也上线了一些相关的功能,我们可以听一下它宣传片上的效果:
PromptSpeaker:基于自然语言描述的说话人生成
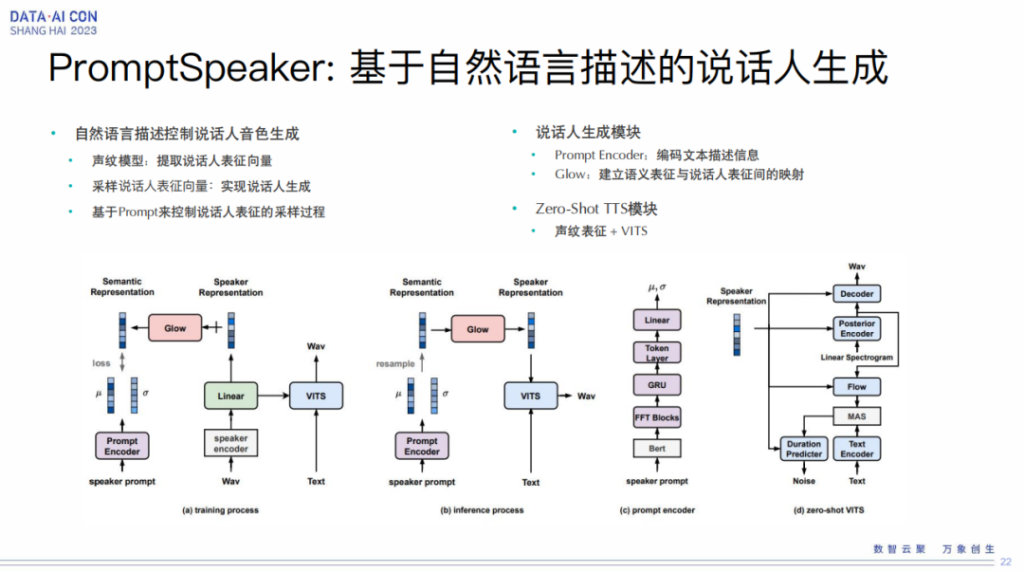
要实现刚才那些效果,需要我们技术的支撑。第一个我们基于自然语言去生成说话人,也就是我们去生成一个新的说话人。为了证明这个新的说话人在我们的训练集里不存在,我们可以从口算相似度上去度量一下,所以这块我们也是基于声纹模型进行采样,但是声纹模型跟我们人工的描述之间要做对齐,所以这块我们就用了 Glow 去建立语义表征和说话人表征之间的映射,然后再加上 zero-shot TTS 的模块,我们就可以生成我们想要的音色。当然这个要做稳定的话,我们有非常多的调优的过程,这就是基于自然语言的描述说话人的生成。
PromptStyle:基于自然语言描述的风格迁移
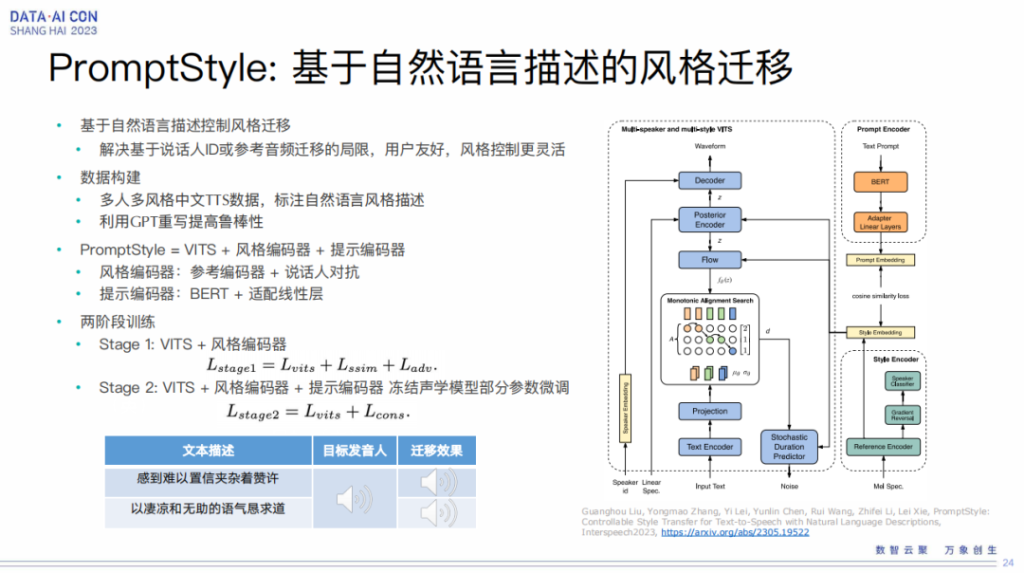
另外我们也可以做到基于自然语言进行风格的迁移,也就是说风格迁移我们可以基于双人ID,也可以基于reference,也可以基于风格,比如感到难以置信地夹杂着赞许这样的风格去生成一些音色。
这块我们做了一个叫做 PromptStyle 的系统,这个系统需要我们先构建数据,然后我们有人工的标注,同时我们用 GPT 进行扩写,去增加它的鲁棒性。我们这个系统是一个位次加分隔编码器和提示编码器的思路,这个思路其实最终调完之后还是相对比较稳定的,可以得到自然语言描述的这种风格迁移。
PromptVC:基于自然语言描述的语音转换
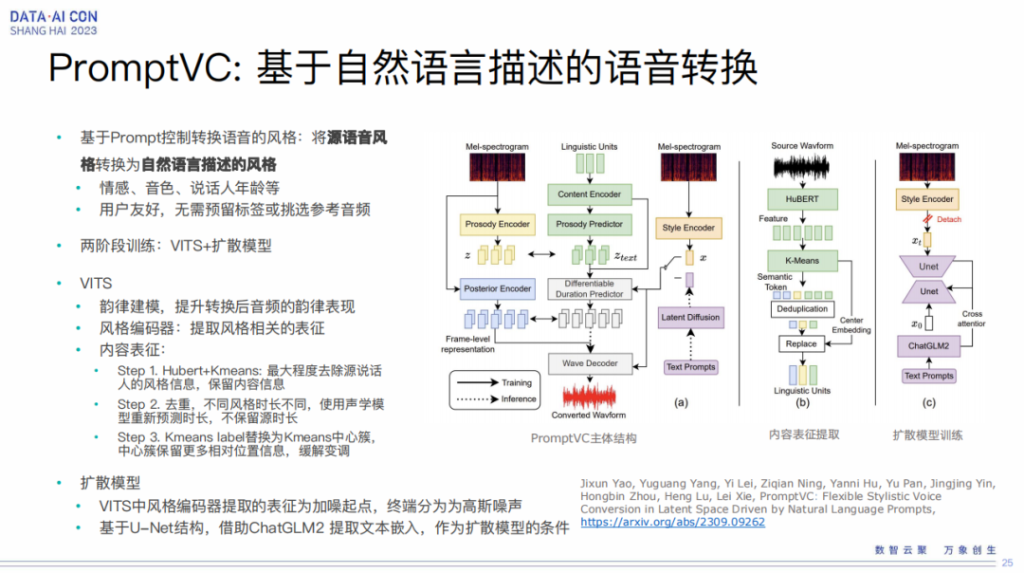
除了可以做文本、做输入、做合成之外,其实我们也可以做语音转换,语音转换就是我们可以将原语音的风格根据描述转成我们的目标语音。

语音转换实际上也是我们的一个重点研究课题,在这块我们主要围绕的是高表现力的语音转换,其实不管在游戏还是影视的配音里都是需要的。跟爱奇艺合作我们可以做到这样的效果,比如我们找一个泰国的配音演员,把一个影视剧一配到底,然后我们用变声技术把他转成不同的角色,例如爱奇艺已经在泰国上线的赘婿:
DualVC:实时流式语音转换
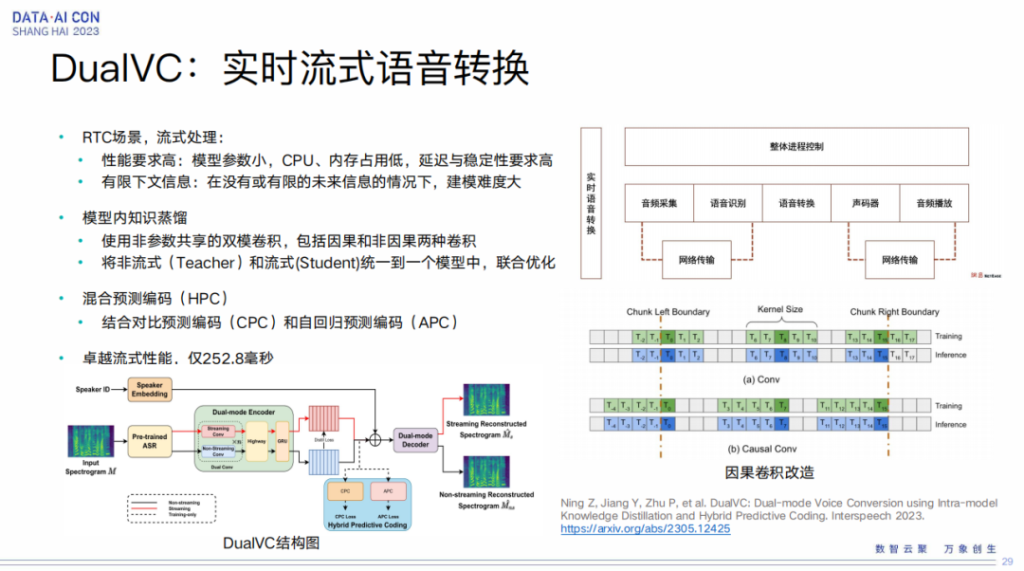
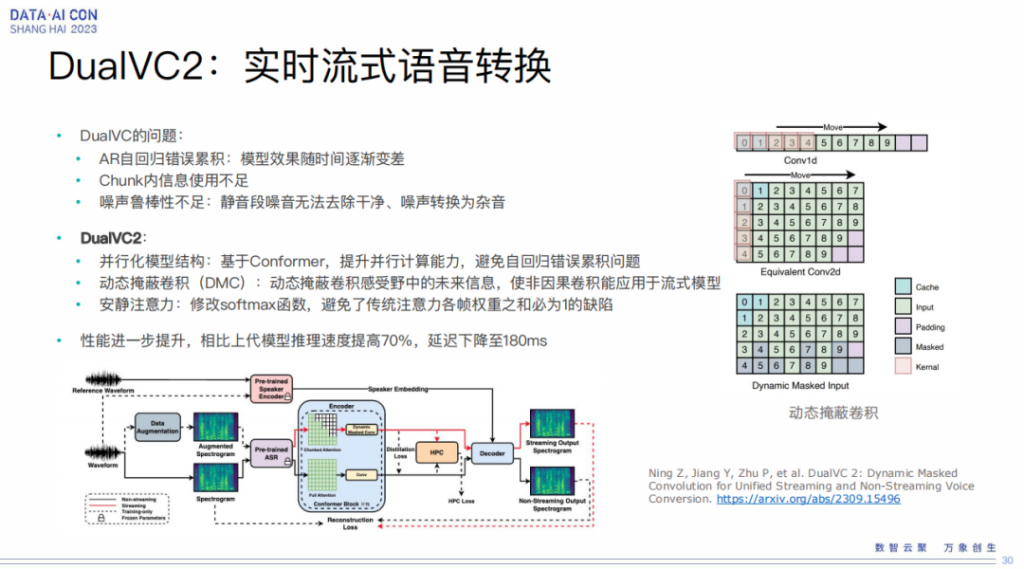
此外我们也需要做流式的语音转换,比如我在做报告,但是下面大家听到的是另外一个女生的声音,实时的同步做。这方面我们也跟网易伏羲团队做了相关的工作,大家可以参考一下我们的论文,这其实可以在游戏里边进行广泛的应用。

同时我们也做了高表现力的语音转换,可以做到比如让我来唱歌。
多任务语音生成大模型
最后我简单给大家介绍一下我们在语音大模型方面的一些工作。

沿着 VALL-E 大模型的路线,我们做了一个 Vec-Tok Speech 的框架,我们结合了连续和离散表征的优势,可以做到各种各样的下游任务,以及多种风格。我们可以用 3 秒钟的说话人的音色,再加 3 秒钟的目标的韵律进行组合,做到各种各样的风格。
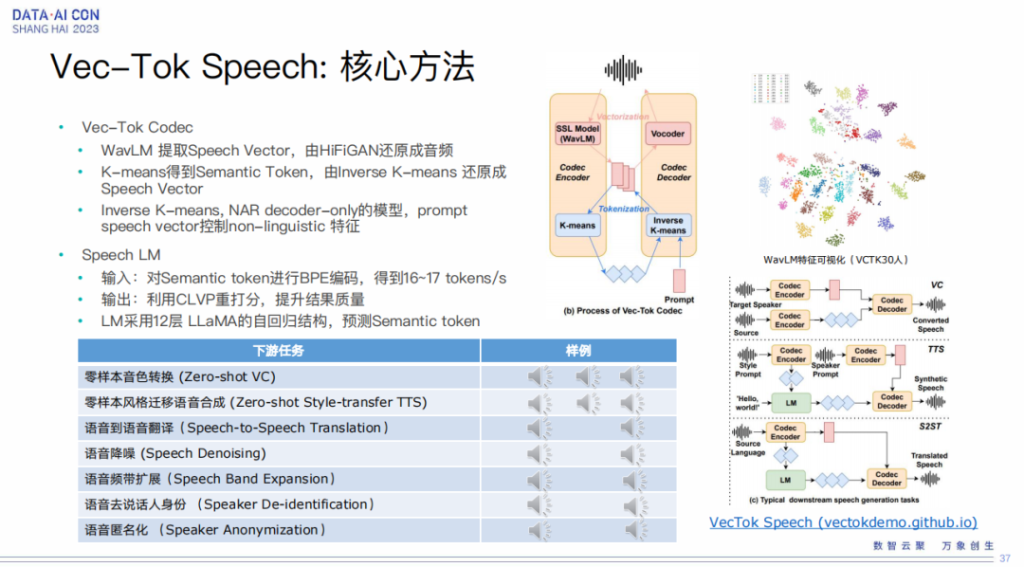
这里边也可以做各种各样的下游任务,比如翻译任务、降噪任务、平台扩展,包括语音转换,还有匿名化等等。
Vec-Tok Speech:Zero-shot Style Transfer TTS
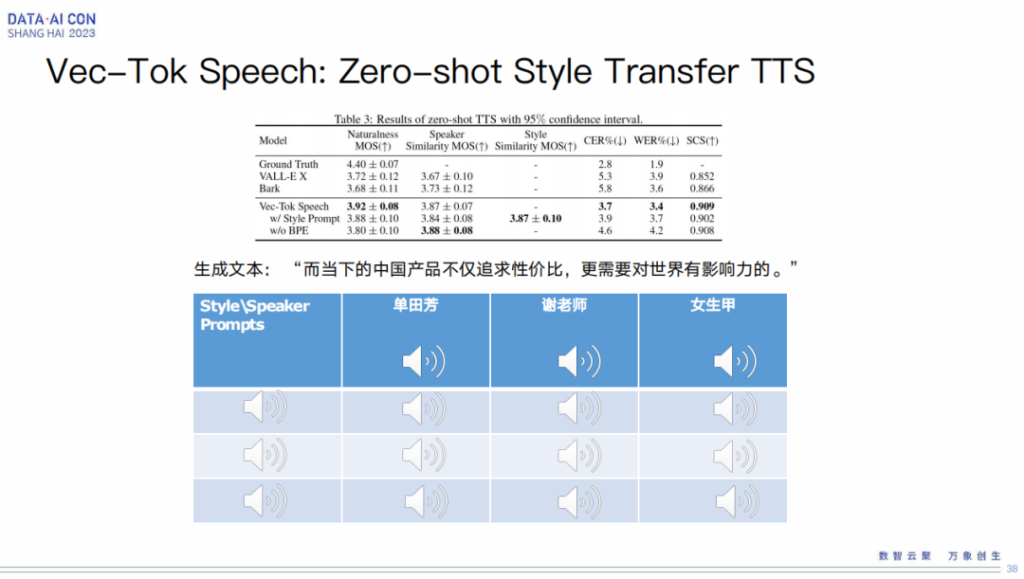
在 zero-shot style transfer TTS 方面,这其实是我们的一个亮点。
这块大家可以关注下我们发表的《Vec-Tok Speech》这篇论文,已经放在了网上,是我们跟喜马拉雅合作的一个成果。