
作者:张敏
编辑:麦吉哈
在Data & AI Con Shanghai 2023的“数据工程与大模型落地实践”分会场中,张敏老师为我们分享了「大语言模型下的机器翻译研究与实践」,让我们对机器翻译有了更深入的了解。
ChatGPT的出现让大语言模型成为研究热点,并成为解决各类NLP任务包括机器翻译的新范式。张敏老师他们先对ChatGPT的翻译能力进行了自动指标评估和人工评估,尝试总结大语言模型进行翻译的优势并结合他们在知识指导机器翻译上的积累,提出将知识封装到大语言模型中进行各种机器翻译任务。最后,张敏老师介绍了在开源大语言模型LLaMA上进行机器翻译SFT的进展和结果。
提纲
这是我的一个提纲,会先给大家介绍一下机器翻译和大语言模型,后面分四个层次介绍,一个是大语言模型的翻译质量究竟怎么样,通过我们翻译中心的人工译员做了一些比较高质量的人工评测,大家会看到大语言模型在翻译上跟传统模型的一些区别。
之后我会介绍我们做的三个工作,一是我们通过知识图谱来指导大语言模型提升翻译质量,二是我们基于大语言模型来做机器翻译的质量评估,还有一些做自动的译后编辑IPE。最后会介绍我们基于开源大语言模型Llama针对机器翻译做的一些SFT工作。
机器翻译和大语言模型介绍
机器翻译介绍
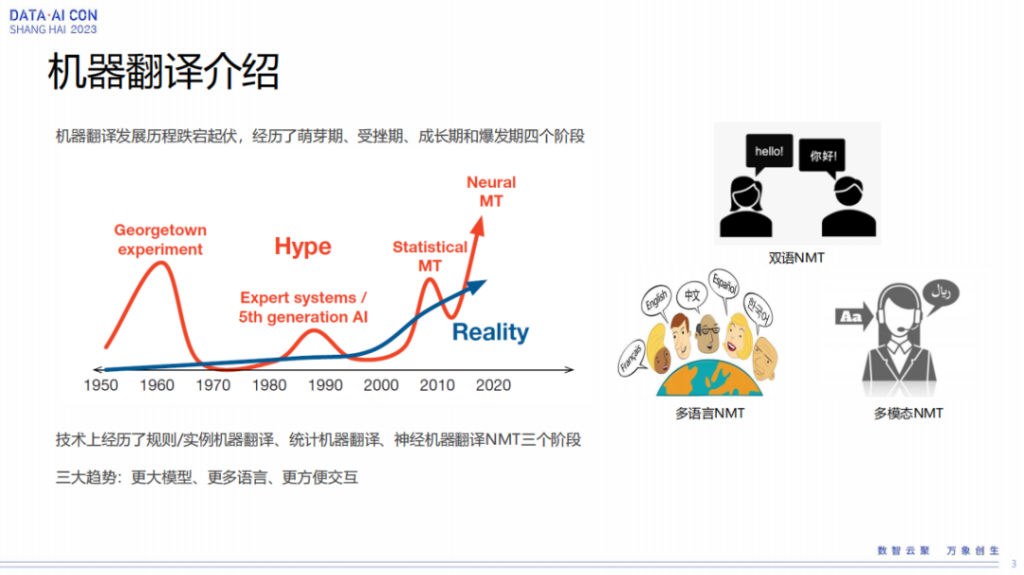
机器翻译的发展历程其实也是非常跌宕起伏,跟AR发展历程非常类似,它真正的发展是到了深度学习以后,有一个明显的进展。
之前基于规则/实例还有统计,机器翻译偏研究为主,离真正落地距离还是远一些。另外我们可以看到机器翻译的三个趋势,更大的模型、更多的语言和更方便的交互。语音交互这块可以通过语音翻译直接让翻译结果呈现出来。
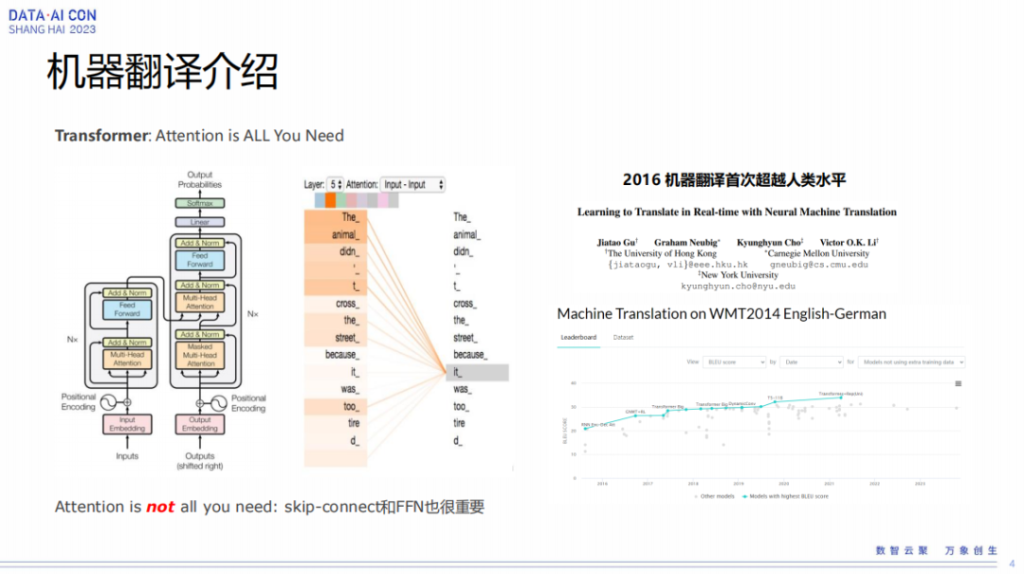
在翻译里最有名的一个模型是Transformer模型,Transformer模型提出以后对翻译效果确实有了非常大的提升。2016 年机器翻译首次超过人类水平,当然这个可能也是一些宣传,机器翻译的质量可能还是没办法做到直接交付。
右下角那张图是WMT2014 English German,这是机器翻译里面非常有名的一个数据集。我们能看到历年来翻译效果的一个提升,可以看到Transformer模型对效果的提升还是非常显著的。但是也有一点,Transformer模型之后翻译效果的提升其实就没有那么多了。在机器翻译这一块,大家也是希望大模型出来以后,我们能看到大模型对机器翻译也有一些非常正向的推动。
Transformer 模型实际上是一个encode和decode模型,encode和decode后来的发展也非常有名,像后面的bot是基于encoder模型,现在非常热的大模型是基于decoder模型。这里面提到的attention、skip-connect和FFN也都非常重要,如果去掉一部分,它的效果也没有那么好。

我们总结一下目前机器翻译的问题,包括领域、实体、过译、漏译和风格等问题,上图举了一些例子,我就不具体展开了。
目前机器翻译主要的业务流程是TM库,这是我们历史翻译的记忆库,如果碰到相同的翻译,可以直接出翻译结果。MT是做机器翻译,MT结果之后还有QE跟APE的过程,QE是对机器翻译质量做一个评估,如果OK的话就直接做交付,如果不是那么好,那么我们后面会接一个APE,自动的译后编辑,或者接人工编辑这样一个过程。
大语言模型介绍
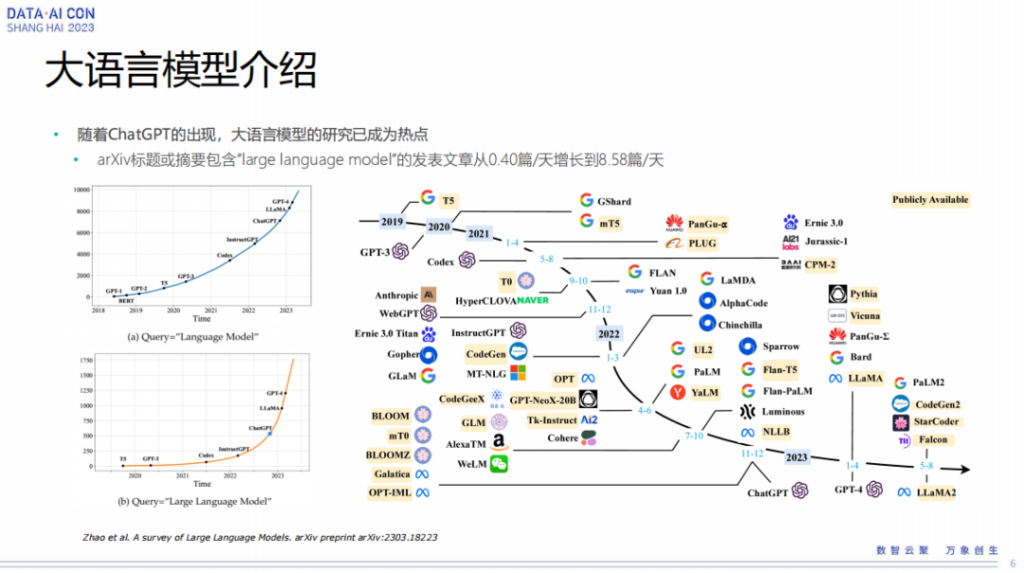
大语言模型随着ChatGPT的出现已经成为了研究热点。这张图可以参考一下,可以看到大语言模型出来以后,发展非常迅速,各种大模型都已经出来了。
大语言模型的翻译质量评估
刚刚我们简单介绍了一下机器翻译跟大语言模型,那么我们接下来会介绍一下大语言模型的翻译质量。
这个是我们今年上半年做的一个工作,我们跟翻译中心的译员一块来评估,当时就是通过大语言模型做机器翻译。那么我们来看一下结果,大语言模型的评估到底是什么样的情况。
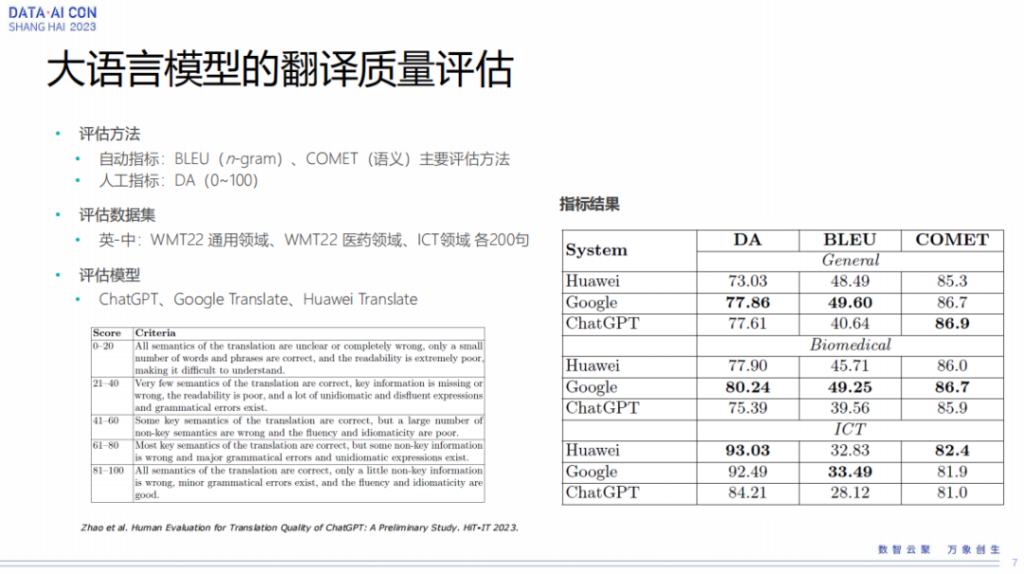
我们选了两种评估方法,一个是自动指标,在机器翻译里面BLEU是一个非常有名的基于n-gram字词级别的评估方式,后面还有COMET指标,是基于语义的一个评估方法。从机器翻译的效果来看,其实最有效的是人工打分的指标,当然这个地方是需要比较专业的译员来做这件事情。
评估数据集我们选择了WMT22通用领域、WMT22医药领域和ICT领域三个领域各200句。因为做人工评测数据量太大,人工消耗也非常厉害,所以我们就各选200句。从机器翻译角度来看,有200句已经能看到一些机器翻译上的问题了。
评估模型我们选择了ChatGPT的翻译结果、谷歌的翻译结果和我们自己的翻译结果。上图下面那个表是人工打分的一些指标,采用百分制,百分制以后会定一些比较细的准则,从0-100分怎么去打。我们可以看一下三个系统的得分情况,从BLEU指标来看,ChatGPT其实比我们基于Transformer模型的指标都要低一些。但是从语义上面来看,也就是commit指标上来看,它其实并不差,特别是在通用领域commit指标ChatGPT反而是最高的。commit指标跟人工指标的打分更一致一些,也就是从人工观测来看,ChatGPT的指标其实没有BLEU表现那么差,这也能看出ChatGPT的翻译可能更偏口语化一些。如果只从字词的匹配度来看,它的BLEU指标确实低一些,但如果从语义上面来看,它的指标其实还算是基本OK的。

我们可以简单看两个case,第一个case实际上是一个俚语的翻译,在这个情况下,ChatGPT的翻译非常准确,它能够把俚语翻译得非常好。但是对于Transformer模型,就是这种encode跟decode模型,如果见这种语料比较少就很难翻译好,只能单纯的逐字翻译,所以效果就比较差一些。
下面那个例子是我们华为这边ICT领域的一个专业术语,从专业术语上面来看,华为翻译见过这个专业术语,但ChatGPT和谷歌没见过,所以就很难把这个翻译正确。
大语言模型+多语言实体知识图谱

因为我们做机器翻译研究时看到它对一些专业术语的翻译没那么好,所以我们很自然的一个想法就是,我们是不是能够通过多元的知识图谱去提升大语言模型的翻译能力。我们希望把知识图谱通过prompt把它引入进去,然后去提升翻译的效果。
这里我们看一个例子,光纤跟黑光纤,特别是黑光纤它实际上不能直接翻译,它是一个非常专业的术语。如果是专业的术语,我们交给ChatGPT翻译它也没办法做到翻译这么准确,它可能就是字面上的翻译。
在翻译领域,我们已经构建了大量的多元知识图谱,即实体对,针对实体对source我们做一个NER,做一个实体的识别,通过实体识别,我们再做一个搜索,去找到这样的实体pair,然后我们通过Prompt的引入进行翻译,这样它就可以正确的把这种实体词翻译出来。
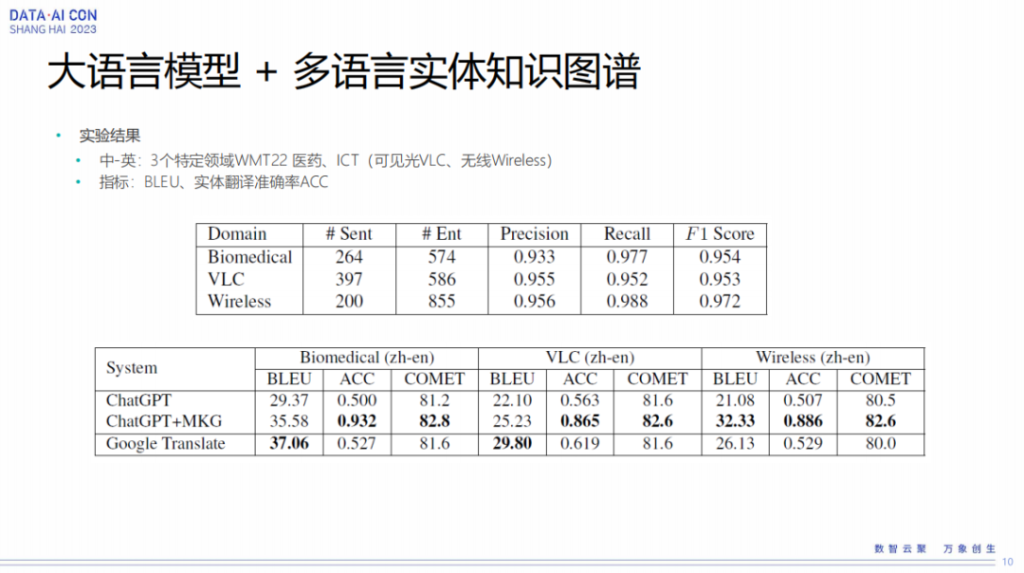
我们针对自己三个领域的数据集,WMT22医药领域和ICT我们自己的可见光跟无线领域做了一个实验。
从实验结果来看,我们通过把多元知识图谱引进去以后,实体的翻译准确率会有一个非常显著的提升,原来可能只有50%,或者50%多,现在可能到百分之八九十。同样我们拿谷歌的翻译作为一个参照,也可以看到谷歌翻译的准确率跟ChatGPT差别不是特别大,而且特别是在一些比较强领域上效果会更明显一些。像在无线或者可见光领域,这种术语的公开数据集非常少。然后也可以看到,通过把这个数据引进来以后,在特别专的领域,ChatGPT加上这个图谱以后,它的BLEU值甚至比谷歌还会更高一些。

上面是两个例子,可以简单看一下,这里有一些非常专业的词汇,比如可见光光波、单模光纤,这些词汇我们通过把它引进多元知识图谱,它的翻译准确率就提升非常明显。红色表示翻译错误,蓝色表示翻译正确,可以看到翻译的准确率提升非常显著。
基于大语言模型的机器翻译质量评估(QE)

刚才我们是做机器翻译,另外我们也考虑基于大语言模型做机器翻译的质量评估,刚才有提到机器翻译之后有一个质量评估,评估这个翻译的质量到底好不好。这地方实际上是说,我们直接输入的是一个source,一个MT结果,我们通过构造一个prompt,让大模型去判断翻译的两个pair是不是OK的。
在构造prompt的时候,我们有些背景知识,我们构建了三类的prompt,第一类是我们判断一下MT结果的翻译流畅度是不是OK的。第二个prompt我们从自粒度翻译相似度去考虑,去判断它是不是逐字翻译,翻译是不是OK的。第三个prompt是判断这两个句子的翻译是不是OK的。我们构建了三个prompt来做质量的一个评估。
大模型里面可以做COT思维链这种模式去增加它的效果,这地方我们做了两个COT,一个是我们把流畅度引进来,另外一个是我们把字的相似度引进来。另外就是我们把所有的三个都引进来,实际上从这个实验结果来看,我们发现做COT的时候,有两个的时候的效果是最好的,把三个都引进来以后,大模型的效果反而没那么好。
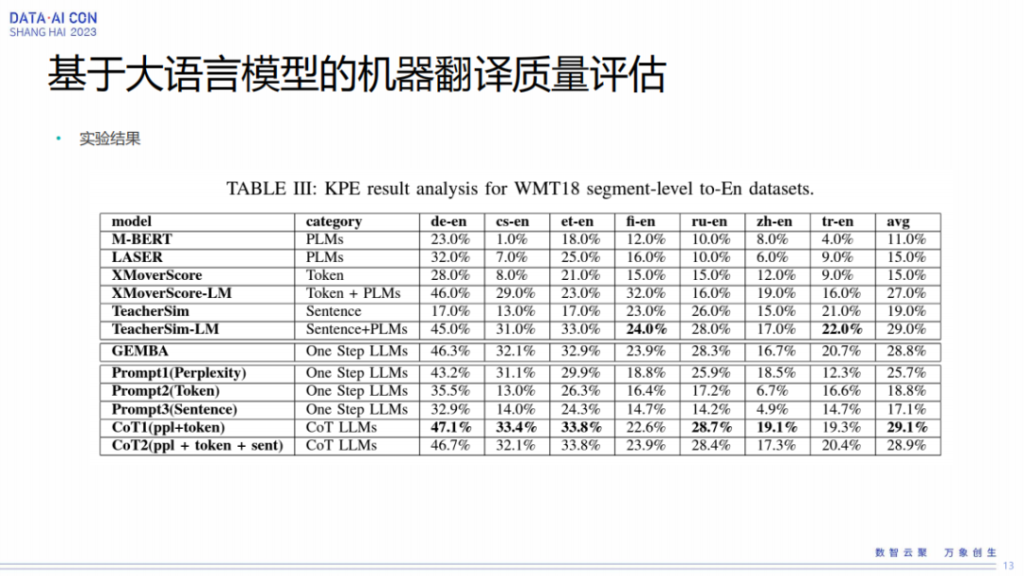
这里可以看一下,这是我们在WMT18的G级别质量评估上面做的一个实验。通过我们的实验,可以看到两个prompt做COT的时候效果是最好的,3个它效果反而有些下降。
基于大语言模型的实体自动后编辑(APE)

接下来我们大模型进一步做了实体的自动译后编辑,自动译后编辑是我们拿到source跟MT之后,对MT结果做进一步的优化。那进一步的优化我们怎么做?其实刚才说到我们在翻译里面这种实体词的翻译也非常重要,所以我们把实体词通过多元知识图谱把它引进来,引进来以后第一步实际上我们做了一个质量评估,我们通过这个实体词是不是能够在MT结果里面被正确的翻译,可以找到这些翻译可能存在问题的实体词。有了这些实体词后,我们通过MKG把这个图谱引进来,然后让它作为prompt大模型自动去修复这些错误,比如哪些东西犯错了,让大模型再去给它优化一次。
比如上面这个例子,像螺木岛一开始翻译的时候是翻译错了,翻译错了后,我们作为prompt把它引进去以后,就可以把它翻译正确。当然做APE这地方有个难点,就是这个词被翻译错了以后,我们不知道它错了什么东西,另外我们也不知道它错误的位置在什么地方,所以用大模型自己去修复这个问题,反而可能更灵活一些。
图片右侧可以看一下,我们在WMT19数据集上能够看到,我们在英中跟英德两个语种上面都做了一个实验,这个结果是说我们把实体修复正确的比例,ICC原来大概只有50%多的准确率,修复完以后,我们可以把它的准确率提升到百分之七八十。也就是大模型其实也不能保证,即使我们找到正确的实体,告诉大模型让大模型去修复,大模型也不能100%的修复,不能保证100%正确。另外就是从BLEU值来看,通过这样修复以后,我们在英中这个场景上面比较明显,但是在英德上面BLEU值反而有些下降,也就是让大模型去修了以后,这个实体词修对了,但整个句子的翻译质量反而下降了。这也是比较有意思的一个点,我们也在继续优化,因为这个地方跟大模型的翻译质量关系没那么大。我们直接用大模型来做翻译的话,翻译在英德上面的BLEU值其实跟这边的系统还是非常相当的。
上图下边有几个例子,可以看到我们把这种有翻译错误的词引进去以后它的翻译是正确的,但是有时候把这个引进去以后,大模型实际上也会有问题。
基于开源大语言模型SFT
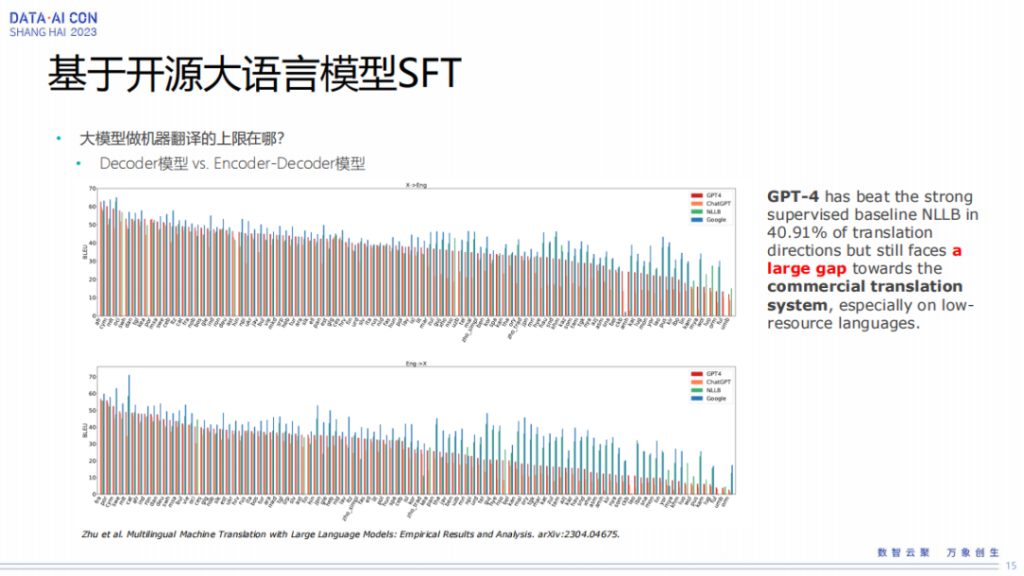
接下来我们介绍一下基于开源大语言模型做的SFT工作,我们想探讨一下大模型做机器翻译的上限在什么地方,因为它实际上一个是decoder模型,一个是encoder跟decoder模型。
但是从之前我们看到的一些公开文献来看,encode跟decode大模型的翻译结果特别是BLEU值跟基于Transformer的模型实际上是有一个比较大的gap。即使GPT4,它在很多语种上面比Transformer模型依然要低。
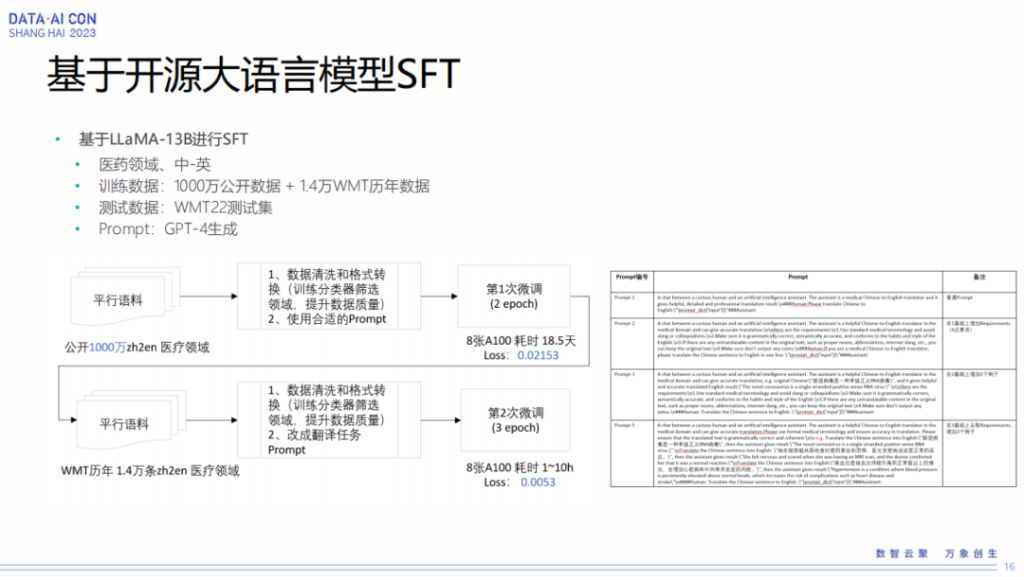
所以我们基于LLaMA-13B做了SFT工作,我们刚才也提到,一个是做这种大模型需要的计算资源特别大,我们就希望在一个特定的领域上面去探索一下大模型到底能达到什么样的程度。我们在医药领域选择了一个中英的数据,训练数据我们把它提到1000 万,因为之前基于大模型做翻译SFT的可能也就是在几十万或者到百万这个级别,那我们把它做到一千万看一下它到底能到什么样的性能。另外因为我们的测试集是WMT医药测试集,所以我们增加了1.4万的历年的数据。
在做SFT时也需要一些prompt,我们就用GPT 4生成一些prompt做引入翻译能力。所以这里等于我们训练的时候做了两次SFT,第一次是拿1000万的数据来做SFT,第二次是拿相关性更强的WMP数据来做SFT。
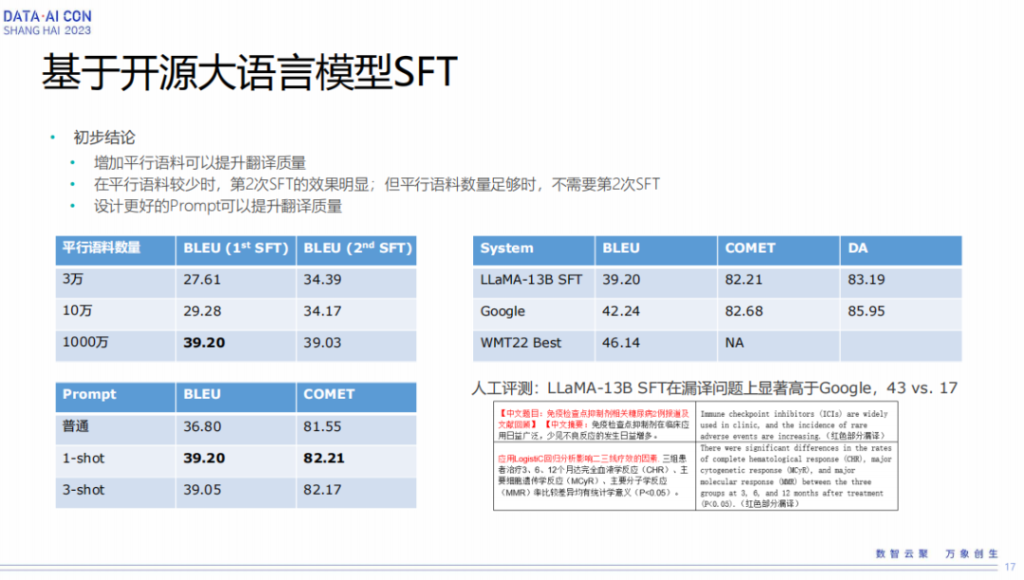
基于上面的实验,我们得到了一些初步的结论。我们从一开始做3万的平行语料到10万,然后到中间我们加到100万到1000万,从这个地方来看,增加平行语料对翻译质量的提升确实非常明显。在3万的时候BLEU值大概只能得到27,我们把它提到1000万的时候,BLEU值大概可以到39。后面我们针对性做第二轮SFT时,可以看到数据量特别大的时候反而对效果提升没有什么帮助,在数据集平行数据少的时候提升会比较大一些。
接下来我们再看一下基于prompt有什么好处。如果一个普通的prompt直接做翻译,它的翻译结果可能没那么好,可能就是36 BLEU值的效果。
1-shot是说我们在提供prompt的时候给一个翻译的示例,给了翻译示例后再让它去翻译,1-shot的时候达到了最好的结果,3-shot的时候结果反而会差一点。即使是这样一个情况,我们再跟谷歌或者是跟一些WMT最好的结果比,它在BLEU值上面依然会有些差距。跟谷歌比,它大概还有3个BLEU的差距,跟WMT去年最好结果比可能会有将近7个点的差距。
后面我们做了一下人工评测,基于LLaMa SFT做完以后它的效果跟谷歌比为什么差,我们发现一个最大的问题,是在漏译问题上明显高于谷歌,在我们的测试集里面大概有43个漏译,在谷歌上面大概只有17个漏译。在下面这个例子里面可以看到,标红的地方都是大模型发生漏译的一些句子。