
Dataset Introduction
The Multi-speaker Emotional Speech Dataset, an open-source resource released by Magic Data, is designed for applications in speech emotion modeling and large-scale model training. It contains expressive emotional speech samples covering six fundamental human emotions. The textual content of each utterance is carefully aligned with its corresponding emotion, and the recordings are contributed by multiple speakers. This dataset provides an excellent resource for research on speech emotion recognition, emotional speech synthesis, and related fields.
Core Applications
This dataset is particularly well-suited for the following research areas and tasks:
- Speech Emotion Recognition: Provides high-quality labeled speech data for training and validating emotion classification models.
- Emotional Speech Synthesis: Supports the training of speech generation models under multi-speaker and multi-emotion conditions.
- Multimodal Conversation Systems: Improves the capacity of large models for emotion understanding and expression.
- Model Evaluation and Benchmarking: Serves as a benchmark dataset for evaluating and comparing model performance.
Dataset Content
This dataset comprises the following key components:
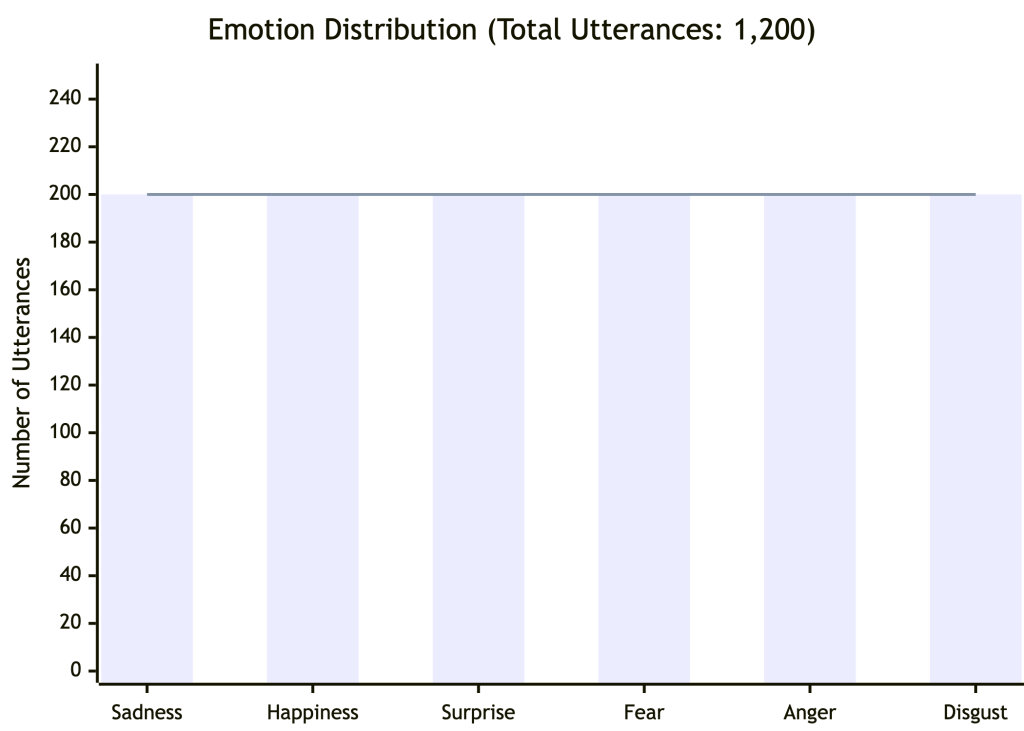
- Speech Samples: 1,200 Chinese utterances covering six basic emotions.
- Speaker Information: 10 speakers (5 male and 5 female) with varied vocal timbres.
- Emotion Categories: sadness, joy, surprise, fear, anger, and disgust.
- Text–Emotion Alignment: Each sentence is carefully aligned with its designated emotion type, ensuring semantic-emotional consistency.
Recommended Use
Intended Audience:
- Researchers working on speech processing and synthesis
- Teams developing multimodal AI models
- Project teams focused on affective computing and interaction design
Research and Application Areas:
- Model Training: Can be used as the main dataset or as a supplementary resource for fine-tuning pre-trained models.
- Cross-Speaker Generalization Evaluation: Assesses model performance on previously unseen speakers.
- Evaluation of Emotional Speech Synthesis: Enables comparison of emotional expressiveness across different TTS systems.
- Enhancing Human–Computer Interaction Systems: Supports the improvement of emotional responsiveness in conversation systems.
Recommended Application Scenarios:
- Development of speech emotion recognition systems
- Emotional speech synthesis across multiple speakers
- Building emotion-aware conversational agents
- Academic research and algorithmic competitions
Technical Specifications
| Item | 描述 |
| 语种 | 中文 |
| Speech Parameters | 16 kHz, 16 bits, WAV format |
| Channels | Single channel (mono) |
| Number of Speakers | 10 speakers (5 male and 5 female) |
| Emotion Categories | sadness, joy, surprise, fear, anger, disgust (6 categories) |
| Total Number of Utterances | 1,200 utterances |
| Data Distribution | 20 utterances per speaker for each emotion, evenly distributed |
Notes
- This dataset is intended solely for non-commercial academic research and technical development, and its use for any commercial purpose is strictly prohibited.
- For commercial applications, please contact the Magic Data team to obtain authorization.
- It is advisable to evaluate model generalization in diverse environments to ensure the robustness of research outcomes.
- The dataset may be combined with other speech resources to improve system robustness.
Sample
anger:
surprise:
For access to thousands of hours of commercial datasets, please contact business@magicdatatech.com.