
此数据集包含180个小时的中文普通话对话音频和转写文本,内容为由663名说话人提供的自由对话语料。
样本:
描述
开源数据集MagicData-RAMC介绍
精细标注的中国大陆普通话对话式语音数据集
180小时的普通话对话,训练集、开发集和测试集分别为150、10和20小时。
数据采集
声学环境为不足20m2的房间,混响时间(RT60)小于0.4秒。 环境噪音水平低于40dB(A),录制过程中环境相对安静。
音频由爱数智慧在主流的智能手机上录制,其中Android和IOS系统的比例约为1:1。录音均为16比特采样点,采样率16KHz,录音质量高。
转录文本由爱数智慧人工标注并由专业检验员校对。除了正常的语音内容以外,还标注了犹豫、重复、标点、非语言、说话人时间戳等信息,标注质量高、信息丰富。
性别和人口的分布是平衡的。
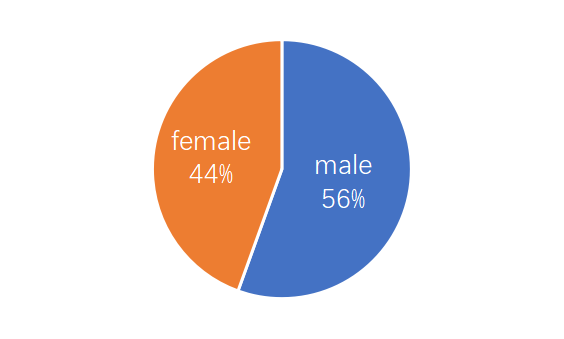
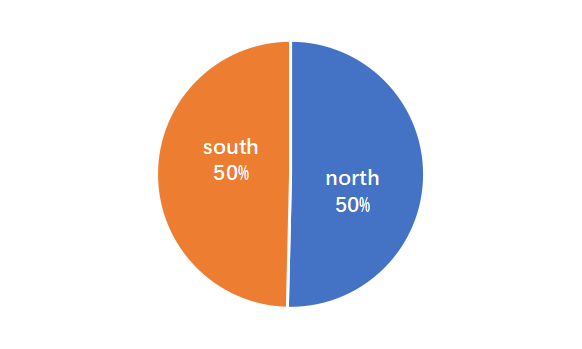
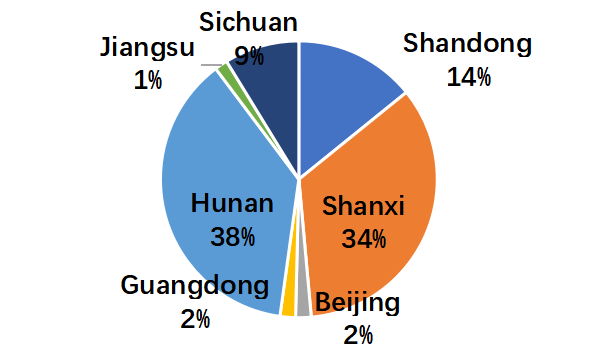
包含各种各样的对话主题。
它包含351个多轮对话,每个对话都是围绕一个主题进行的连贯而紧凑的对话。
它涵盖了15个主题,包括人文、娱乐、体育、军事、金融、宗教、家庭生活、政治、教育、数字设备、环境、科学、专业发展、艺术和普通生活。
它适用于探索对话场景中的语音处理技术。
基线介绍
自动语音识别
We used ESPnet2 toolkit to train a Conformer model. The training data includes 755h of MagicData-READ and 150h of MagicData-RAMC.
我们在开发集和测试集上取得的字符错误率分别为16.5%和19.1%。
关键字搜索
We retrieved 200 keywords, which is provided by MagicData-RAMC, based on the Conformer model and daynamic time alignment algorithm.
开发集的精确率和召回率分别为86.98%和89.57%,测试集的精确率和召回率分别为85.87%和88.79%。
说话人日志
We used Kaldi toolkit to build a speaker diarization system which includes speaker activity detection, speaker embedding extractor and Bayesian HMM clustering. The timestamps are provided by MagicData-RAMC.
我们在开发集和测试集上取得的日志错误率分别为5.57%和7.96%。